Paper Summary Seq2tree
Language to Logic Form with Neural Attention
作者
Li Dong, Mirella Lapata
li.dong@ed.ac.uk, mlap@inf.ed.ac.uk
单位
Institute for Language, Cognition and Computation
School of Informatics, University of Edinburgh
10 Crichton Street, Edinburgh EH8 9AB
关键词
sequence-to-sequence, sequence-to-tree, semantic parsing
来源
ACL 2016
立题
该文涉及的任务是semantic parsing,其目标是将一句话解析为正式的意图表示(比如一个逻辑表达式或者结构化的query)。作者首次将seq2seq引入该任务,并在普通seq2seq的decoder无法考虑逻辑表达式的层次结构的问题上,创造性地提出了层次树decoder。
模型
1. 模型概略
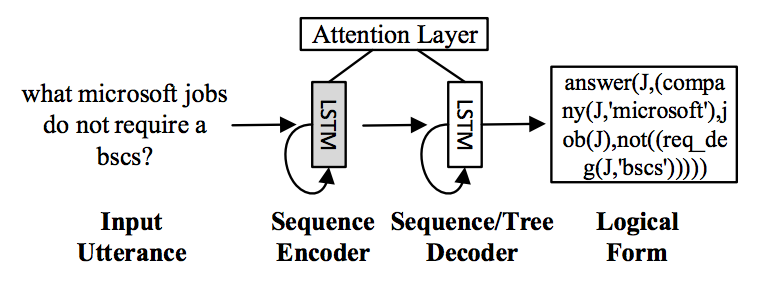 该文要做的事情是把自然语言序列\(q = x_1 \dots x_{|q|}\)映射成逻辑表达式\(a = y_1 \dots y_{|a|}\)。则条件概率\(p(a|q)\)可以分解为:
\(p(a|q)=\prod_{t=1}^{|a|} p(y_t|y_{<t},q)\)
该文要做的事情是把自然语言序列\(q = x_1 \dots x_{|q|}\)映射成逻辑表达式\(a = y_1 \dots y_{|a|}\)。则条件概率\(p(a|q)\)可以分解为:
\(p(a|q)=\prod_{t=1}^{|a|} p(y_t|y_{<t},q)\)
其中\(y_{<t}=y_1 \dots y_{t-1}\)。
2. seq2seq模型
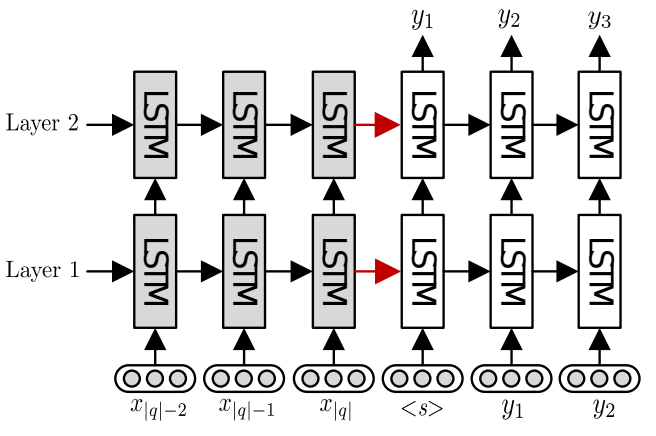
seq2seq模型,深色(左边)的为encoder,浅色(右边)的为decoder。
3. seq2tree模型
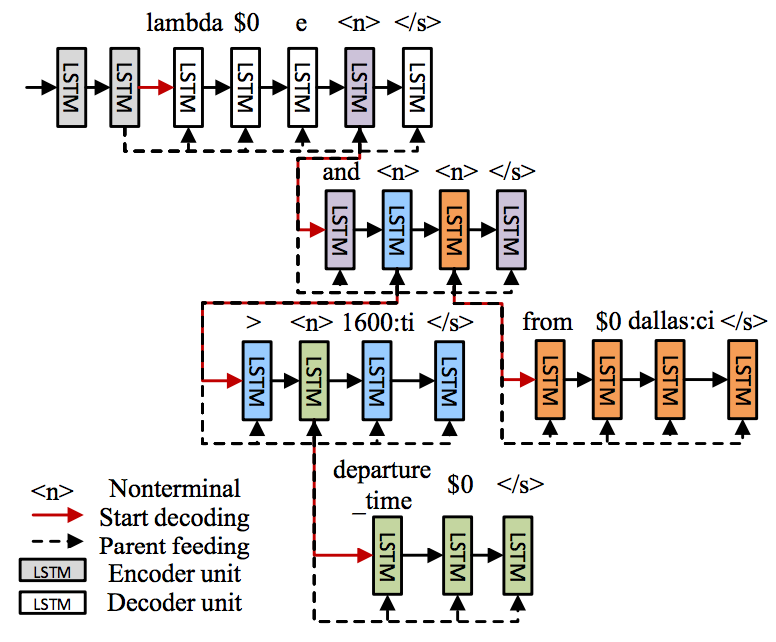
seq2tree的根本改变就是把decoder从一个单纯的序列RNN变成了考虑逻辑表达层次结构的复杂RNN模型。改进的地方就是在decoder的输出词表中加了一个“非叶子结点”<n>,用来表示该处还有子树。比如,上图中的预测逻辑表达式是“lambda $0 e (and (>(departure time $0) 1600:ti) (from $0 dallas:ci))”,每一层圆括号里包着的内容就是一棵子树。所以改进后的层次树decoder,通过先预测第一层,再在第一层的“非叶子结点”的基础上预测下一层,以此类推直到没有“非叶子结点”。整体的解码过程就像一个广度优先搜索一样进行着。
4. attention
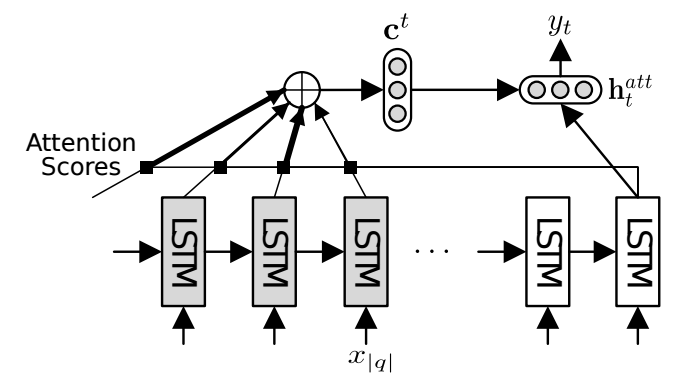
该文的attention计算方法和常见方法有点不一样,它使用decoder中当前hidden state和encoder中所有hidden state计算attention weight。 $$s_k^t = \frac{ exp(\textbf{h}^L_k \cdot \textbf{h}^L_t) }{ \sum_{j=1}^{|q|}exp(\textbf{h}^L_j \cdot \textbf{h}^L_t) }$$ 其中\(\textbf{h}^L_t\)表示当前decoder的隐层状态,\(\textbf{h}^L_k\)表示的是encoder的隐层状态。
根据attention weight计算的context vector为 $$\textbf{c}^t = \sum_{k=1}^{|q|}s_k^t\textbf{h}^L_k$$
decoder层的计算: $$\textbf{h}^{att}_t = tanh(\textbf{W}_1 \textbf{h}^L_t + \textbf{W}_2\textbf{c}^t)$$ , \(p(y_t|y_{<t},q)=softmax(\textbf{W}_o\textbf{h}^{att}_t)^T\textbf{e}(y_t)\) 其中\(\textbf{e}(y_t)\)表示一个one-hot向量,用于获取\(y_t\)的概率。
资源
其实验相关的代码: https://github.com/donglixp/lang2logic
相关工作
semantic parsing的前人工作往往依赖于高质量的词典、人工构造的模板和领域特有的特征等。
简评
seq2seq解决sentence to tree的问题已经不是新鲜事物了,比如 Vinyals做的句法分析的工作,但该文在seq-to-tree模型上的创新让人耳目一新。