SLU Review Introduction
Table of Contents
口语理解基本概念
语音是口语对话系统中最主要的输入,语音识别模块可以将音频输入转换为对应的文字信息。然而原始的文字信息只能被计算机记录,而不能被计算机所“理解”。因此我们需要有一个理解模块,让计算机正确地理解用户(人)所说的话以及后续能够做出适当的回答。口语理解(Spoken Language Understanding,SLU)作为语音识别和对话状态跟踪之间的连接模块,将用户输入的文字信息转换成结构化的语义信息。比如,用户说了一句“帮我查询明天下午从上海开往北京的机票”,其中包含了三个关键的信息:“出发时间=明天下午”,“出发地=上海”,“到达地=北京”。
语义表达
在不同的口语理解系统中,语义信息的表达方式也都可能不一样。本文主要介绍两种常见的语义表达方式(其它方式大多都可以被这两种概括):语义框架(semantic frame),对话动作(dialogue act)。
语义框架
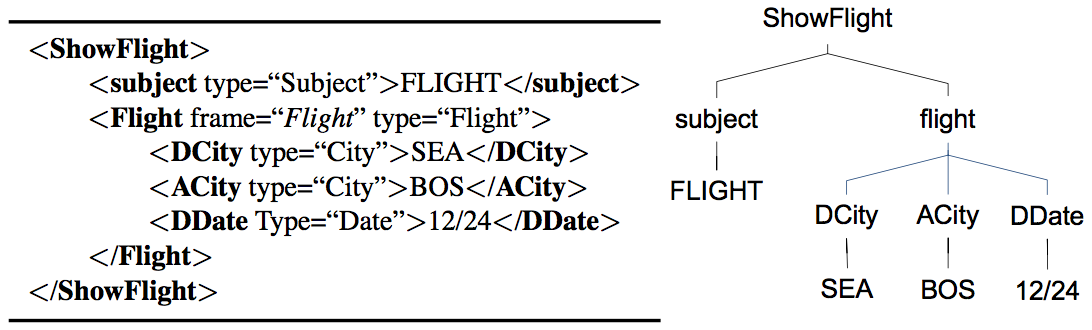
一个特定对话领域的语义结构定义可以以语义框架为基本单位。如图1所示,这是ATIS领域中的三个简化的语义框架示例。其中每一个语义框架包含一系列带类型的成分“语义槽”(slot),而语义槽的类型(type)则限定了它可以被哪一类的值填充。比如 Flight 语义框架中的语义槽“出发城市”( DCity )和“到达城市”( ACity )的填充类型都为“city”,表明该语义槽(也可以被理解为一种属性)允许被填充的值是某一个城市名。

一个输入句子的语义表示就是相应语义框架的一个实例化。如图2所示,输入句子“Show me flights from Seattle to Boston on Christmas Eve”的语义表示是图1中语义框架 ShowFlight 的一个实例化。而且 ShowFlight 中还嵌套了子语义框架 Flight 。当然也有一 些口语理解系统中不允许框架内包含任何的子结构,采用扁平化的结构。这种情况下,语义表示就被简化成一系列的属性值对(或者槽值对),比如图2的数据样例可以表示为:
层次化的语义表示具有更强的表达能力,并且支持框架之间共享一些子结构,比如框架 ShowFlight 和 CancelFlight 都可以包含框架 Flight 。而扁平化的语义表示更简单、易看懂,可以构造更简单的统计模型(比如序列标注模型)。
对话动作
上文所述的语义框架已经具有很好的语义表达能力。这里介绍的对话动作(dialogue act)并非在结构上有超越,而是对于语义表示的侧重点不同。对话动作更加侧重于对“对话行为”的表示。1999年,Traum发展了对话系统中的行为的概念, 考虑了对话的轮次信息以及用行为来表达对话的意义,其中包括请求确认(confirm)、询问(request)等等行为(Traum et al. 1999)。比如,“请求确认”可以用来表示句子“您是明天上午十点出发吗?”的行为,“询问”可以被用来表示句子“这家饭店的地址是什么?”的行为。
但是这种行为表示过于抽象,和更丰富具体的语义槽值信息是分离开的。为了可以同时表达更具体的意思,一种简单有效的语义表达形式——对话语义动作(dialogue act(Young 2007; Thomson 2013)),包括了一句话的行为特征以及其所带的若干简单的语义槽值对(slot-value pair):
其中 act_type 表示一句话的行为(也被成为语义动作类型),它可以是一般的陈述(inform),询问信息(request),以及肯定(affirm)回复和否定(deny)回复,等等。$a=x$和$b=y$表示的是语义动作涉及的语义槽值对,即$slot=value$(slot表示语义槽名字,value为相应槽的值)或者更简单的形式,比如“出发时间=上午十点”。更简单的语义槽值对可以是两种,语义槽为空和值为空,比如 request(phone) 可以表示“这家店的电话是多少”, inform(=dontcare) 可以表示“我无所谓”。另外,表1提供了一些不同语义动作的例子。
可以发现,对话动作更加偏重于“对话行为”的表示,适合于多轮对话的情景。而语义框架有一个很严谨的结构定义,两者互不矛盾且可以进行有效的结合。
| 输入句子 | 语义动作 |
|---|---|
| 从上海到北京的机票 | inform(出发城市=上海,到达城市=北京) |
| 您是明天上午十点出发吗 | confirm(出发日期=明天,出发时间=上午十点) |
| 现在去北京的机票价格是多少 | request(机票价格,到达城市=北京) |
| 对的 | affirm() |
| 不是,你听错了 | deny() |
本体
本体(ontology)是对一个对话领域内的概念化的准确说明,其组成部分为概念、概念的关系、 实例、公理。其既可以和上述的其他语义表示结合,也可以独立作为一个领域的语义表示架构。 概念包含我们之前介绍的语义槽,比如概念可以是语义槽“出发城市、到达城市”,也可以是语义槽值的类型“城市名称”。概念的关系很多,比如上下位、组成部分的关系, 像“出发城市 hyponym 城市名称”。实例就是概念的实例化,比如“出发城市”有“上海、北京、广州”等。公理则是一些事实,像“机票信息肯定有出发城市和到达城市”、“每架航班肯定隶属于一家航空公司”等。关于概念和概念的关系,也还可以有它们的文字说明或者定义,方便人为查看。
本体是对于一个对话领域的定义,提供了该领域的语义范围。首先,本体为开发者设计领域内的语义表示以及口语理解算法提供了参考。其次,本体作为一种人为加工过的知识,对于口语理解的统计学习算法有辅助作用。
口语理解的不确定性问题
语音识别并不能保证百分百正确。语音识别在过去的几十年时间里已经取得了非常不错的进展,采用深度学习实现的语音识别系统(Deng et al. 2013)利用云端的计算优势已经给人们带来了可用的语音识别技术。虽然在单一信道和安静环境下,语音识别系统在非特定人的连续朗诵情况下的识别率已经大于95%,但是在复杂噪声环境下语音识别率不高:人工加噪声的数据下小词汇语音识别目前也只有80%左右(Bocchieri et al. 2013);在真实噪声场景下的大词汇连续语音识别的识别率有时甚至都不到50%,离实际的需求还有很大差距(Liao et al. 2013)。同时,对于新的噪音环境和对话领域的表现鲁棒性也不够理想。
不确定性(或非精确性、不准确性),是人机对话通道的本质属性之一。语音识别本身由于噪声干扰、说话人语速口音等问题具有不可避免的错误。多通道输入的情况下,各个通道都有干扰产生不确定性。在语音识别中的编码转换过程中的误差,再传递到口语理解层,就引发了口语理解的不确定性。另一方面,从认知角度,人类也自然的倾向于用非精确的信息进行交流,因为这会大大的增加信息传输的速度。在信息传输和语义本身具有不确定性的条件下,由机器对用户意图进行理解就成为认知技术的重要范畴之一。它与传统的“语义理解”或“自然语言处理”的根本不同就是将不确定性纳入到研究范畴之内。
语音识别的结果是带有不确定性的,它的输出形式对于后续的口语理解也非常的重要。实际上语音识别的输出并不仅仅是简单的文本句子,因为在给定输入句子语音的情况下,语音识别模块会将其后验概率分配给相应识别出来的词。一种典型的输出形式就是N最佳假设列表(N-best hypotheses list)以及它们相应的概率,其中N是一个整数值,根据需求可以取1或者10等。这样的输出形式使用N个最可能的句子来近似在所有可能句子上的完整分布,这是一种有限的近似。通常情况下,这些最佳假设之间仅仅只有少量的词不同,而且很多都是短功能的词(比如语气词、冠词、其他一些停用词等,像“吗”、“么”、“的”等)。这样就会使得这些最佳假设句子的语义其实是差不多的。此外,一些概率较低的词往往会被这个N最佳假设列表忽略掉。一个N-best list的例子如图3所示。

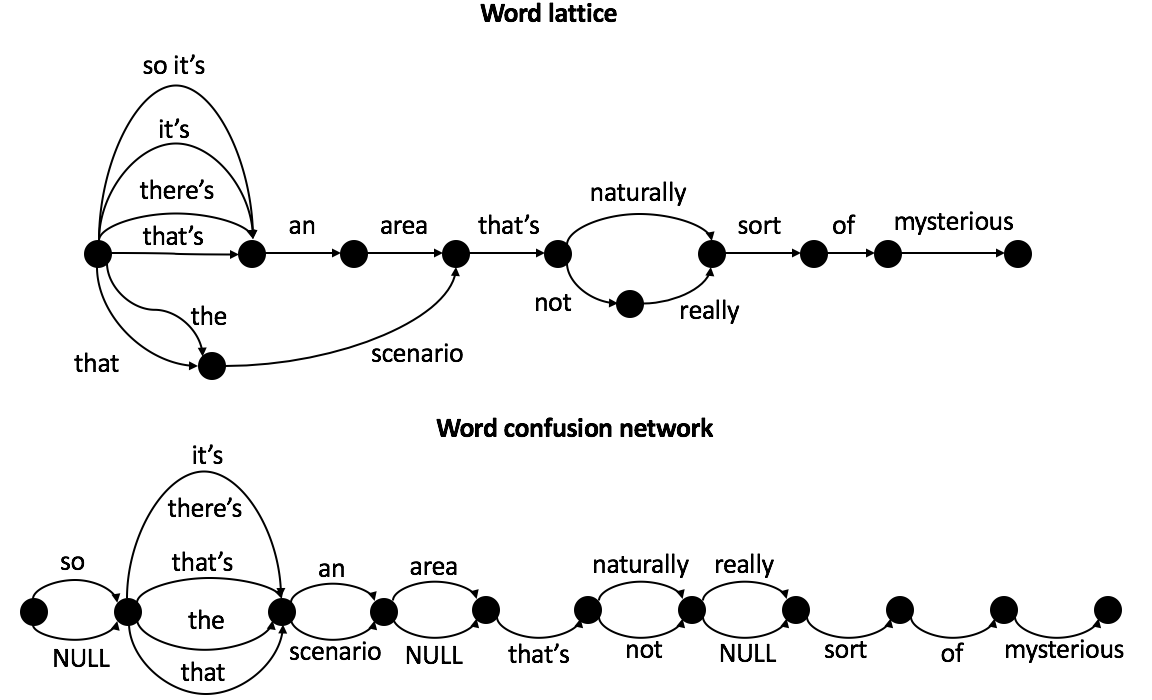
直觉上,语音识别系统输出的关于所有可能词的后验分布的信息都可以被口语语义理解模块利用。词格(word lattice)和词混淆网络(word confusion network)就提供了信息量更大的词识别的后验分布,而不像N最佳假设那样裁剪了得分较低的词。词格是一种可以高效地编码多种可能的词序列的有向图结构(Murveit et al. 1993),如图4所示。所有可能的词序列就是每一条从开始结点到终结点的路径。另外,图中没有显示的信息还包括每条边的权值以及每个词的开始时刻和结束时刻信息。类似词格,词混淆网络也是一个可以枚举所有可能路径的有序图,不同的是它的结构有更多的限制(Mangu et al. 1999)。如图4所示,词混淆网络由一个结点序列组成,每个结点表示的是词边界,且连续的两个结点之间由一些互斥的词连接。需要注意的是从词格转换成词混淆网络时会有一些额外的路径产生,比如图4中“ the scenario area ”在词混淆网络有但不在词格中出现。然而,词格中的路径都会同时存在于词混淆网络中。此外,词混淆网络中还引入了空边 NULL ,用于表示与具体词无关的结点转移。
由此可见,口语理解算法应该对于语音识别结果的不确定性有相应的建模,使得口语理解系统对于语音识别错误具有良好的鲁棒性。
口语理解算法前沿
关于口语理解的研究开始于20世纪70年代美国国防先进研究项目局(Defense Advanced Research Projects Agency, DARPA)的言语理解研究和资源管理任务。在早期,像有限状态机和扩充转移网络等自然语言理解技术被直接应用于口语理解(Woods 1983)。直到20世纪90年代,口语理解的研究才开始激增,其主要得益于DARPA赞助的航空信息系统(Air Travel Information System, ATIS)评估(Price 1990)。许多来自学术界和产业界的研究实验室试图理解用户关于航空信息的、自然的口语询问(其可以包括航班信息、地面换乘信息、机场服务信息等),然后从一个标准数据库中获得答案。在ATIS领域的研究过程中,人们开发了很多基于规则和基于统计学习的系统。
受自然语言处理的影响,大多数研究的建模基础仍然以一个句子(词序列)为基础,而不是更复杂的N最佳假设列表、词格、词混淆网络。关于不确定性建模,我们将在下一节阐述。
规则口语理解方法
早期的语义解析方法往往基于规则,例如商业对话系统VoiceXML和Phoenix Parser(Ward 1989)。开发人员可以根据要应用的对话领域,设计与之对应的语言规则,来识别由语音识别模块产生的输入文本。比如Phoenix Parser 将输入的一句文本(词序列)映射到由多个语义槽(Slot)组成的语义框架里。如图5所示,一个语义槽的匹配规则由多个槽值类型与连接词构成的,可以表示一段完整的信息。
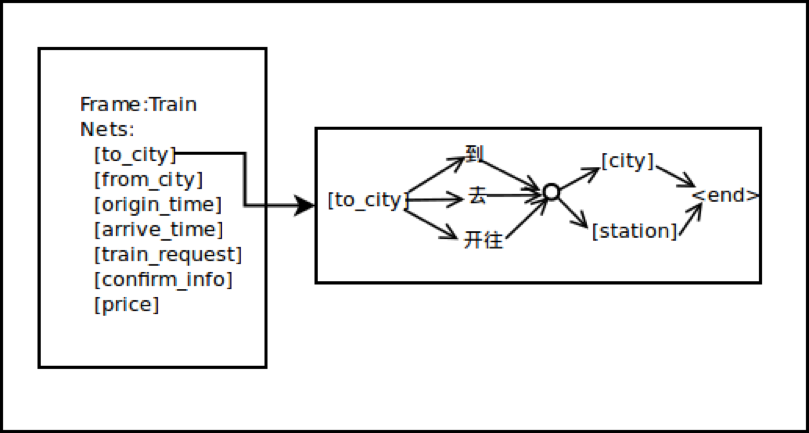
在基于规则系统(有时也称为基于知识的系统)(Ward 1994; Ward et al. 1994; Seneff 1992; Dowding et al. 1993)中,开发人员会写一些句法/语义的规则语法,并用这个规则来分析输入的文本以获取语义信息。这类方法最大的好处是不需要大量的训练数据。然而一个基于规则的系统往往因为这四个原因而很难开发:
- 规则语法的开发是一个易出错的过程。
- 调整一个规则语法往往需要很多轮的迭代。
- 要使得一个规则语法很好地覆盖相应对话领域并取得好的性能,往往需要将语言学专家和工程专家结合起来。
- 当系统中规则数量增多的情况下,规则之间的矛盾冲突会使得规则系统很难维护。
而且在实际的口语对话系统里,语音识别过程往往会产生一定的字错误率(即语音的识别错误)。受制于要匹配完整的语法规则,这种基于规则的语义理解方法在实际的语音技术应用里表现出来的性能会大打折扣。所以面向语音技术的领域,我们要寻找更好更适合的技术。
此外也有一些规则口语理解方法和概率统计的结合,比如组合范畴语法(Combinatory Categorial Grammars, CCG),可以基于标注数据,对大量的复杂语言现象进行统计建模和规则自动提取。由于语法规则的宽松性以及与统计信息的结合,该方法在口语语义理解中的应用可以学习解析无规则的自然语音和带错误的语音识别结果(Zettlemoyer et al. 2007)。
统计方法
基于统计学习的口语语义理解方法则解决了很多基于规则的方法的问题,它可以从句子样例以及它相应的语义标注上自动学习。与手工书写规则相比,数据标注需要的特定专业知识要少的很多。而且统计方法通过一些半监督、无监督学习等方法,可以自动向新数据自适应。然而统计的口语语义理解方法的一个缺点是数据稀疏,因为真实世界的大量标注数据很难获取。
统计口语理解模型可以进一步分为两类:生成式模型(generative model)和判别式模型(discriminative model)。生成式模型学习的是输入$\mathbf{x}$和标注$\mathbf{y}$之间的联合概率分布$P(\mathbf{x},\mathbf{y})$。判别式模型则直接对条件概率$P(\mathbf{y}|\mathbf{x})$进行建模。本文后续会对这两种方法进行区分。
对齐与非对齐数据
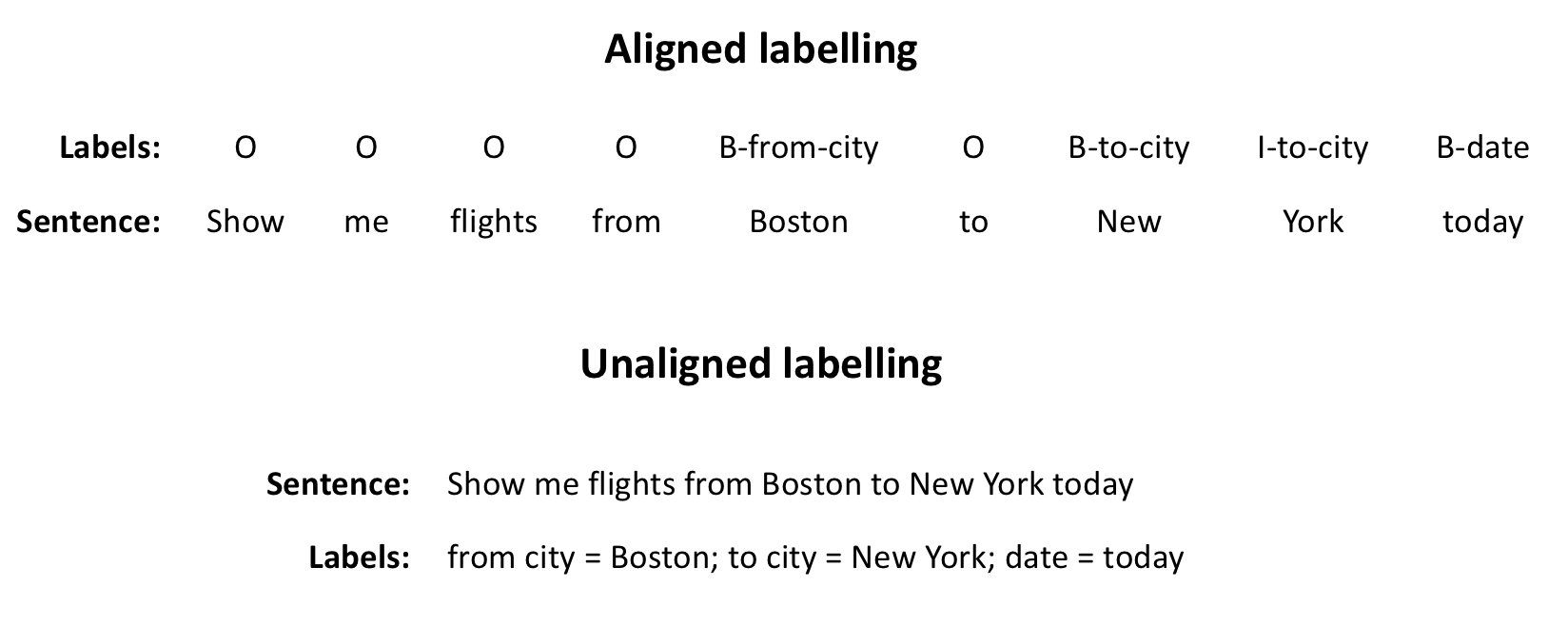
近些年,基于统计学习的口语语义理解方法越来越盛行起来。这些统计方法各有不同,其最主要的不同在于它们的目标是在词序列层次上标注数据还是在整个句子层次上标注数据。词层次上的序列标注方法需要词层次上对齐的数据,而对句子整体进行标注的方法则可以使用非对齐的数据。对齐的标注需要提供输入句子的词和目标语义的一一对应,而非对齐数据不需要这样。图6给出了一个体现对齐数据和非对齐数据(训练数据中)不同的例子,其中引入了 BIO 标签用于对齐标注(BIO标签提供了一种可以对齐标注序列区域的方法,具体如图中所示)。其中对齐数据中每一个词都有它相应额语义标注,而非对齐的数据只对整个句子有一个完整的标注。它们最主要的区别是标注层次不一样,对齐数据是词一级的标注,非对齐数据是句子层的标注。所以非对齐数据的标注应该更廉价。
对齐数据与传统统计模型
基于词对齐数据的口语理解通常被看做一个序列标注问题。即给定词序列(输入句子)$w_1^N=w_1, w_2, …, w_N$,要预测一个等长的语义槽标签序列$s_1^N=s_1, s_2, …, s_N$,其中语义槽标签一般会引入 BIO 标注格式,$N$是序列长度。
随机有限状态传感器(Stochastic Finite State Transducers,SFST)是一种估算词序列和语义标签序列的生成式模型。在(Hahn et al. 2011)中,作者提出了一个基于SFST的口语理解框架$\lambda_{SLU}$,其中包括如下几个部分: $$\lambda_{SLU} = \lambda_{G} \circ \lambda_{gen} \circ \lambda_{w2c} \circ \lambda_{SLM} [ \circ \lambda_{v}]$$
其中$\circ$表示的是FST的合并(compose)操作。$\lambda_{G}$是一个表示语音识别结果(比如词格、或者更简单的1-best hypothesis)的有限状态机。$\lambda_{gen}$是一个将词转换为类别(比如“城市名”、“日期”、“时间”)的有限状态传感器,相当于加入了一些先验知识提高模型泛化能力。$\lambda_{w2c}$将短语转换为语义槽,该模型可以从训练数据中自动归纳也可以人工手写规则。$\lambda_{SLM}$表示的是统计语义槽序列的语言模型,$p(w_1^N, s_1^N)=\prod_{n=1}^N p(w_n, s_n | h_n)$,比如三元组语言模型情况下$h_n=(w_{n-1}, s_{n-1}),(w_{n-2}, s_{n-2})$。$\lambda_{v}$是一个将槽值进行归一化的转换(一般基于人工规则),比如对数值的归一化。
此外生成式模型中,基于短语的统计机器翻译(Statistical Machine Translation,SMT)、动态贝叶斯网络(Dynamic Bayesian Networks,DBN)也被应用到口语理解中(Hahn et al. 2011)。
判别式模型则直接学习给定输入句子的特征表示后标注的后验概率。与生成式模型不同,这类模型不需要做特征集之间的独立性假设,因此这类模型可以更随意地引入一些潜在可能有用的特征。研究表明由于这个原因,在口语语义理解任务中判别式模型会显著地优于生成式模型(Wang et al. 2006)。在对齐数据的口语理解任务中,一般采用基于分类的序列标注模型。该类模型一般有两种输出假设,一种假设输出序列的元素之间是基于输入特征独立的,即$p(s_1^N|w_1^N) = \prod_{n=1}^N p(s_n|w_1^N)$。在该假设下,$p(s_n|w_1^N)$可以采用经典的分类模型来建模,比如最大熵模型(Maximum Entropy,ME)、支持向量机模型(Support Vector Machines,SVM)(Raymond et al. 2007)。另外一种假设是输出序列的元素之间是基于输入特征相关的,比如最大熵马尔科夫模型(Maximum Entropy Markov Models,MEMM)(Hahn et al. 2011)、条件随机场(Conditional Random Fields,CRF)(Lafferty et al. 2001; Raymond et al. 2007)。其中最大熵马尔科夫模型和条件随机场都可以被描述为如下的条件概率公式: $$p(s_1^N|w_1^N) = \frac{1}{Z} \prod_{n=1}^N exp(\sum_1^M \lambda_m h_m(s_{n-1}, s_n, w_1^N))$$ 其中$h_m(s_{n-1}, s_n, w_1^N)$是考虑了输出元素一阶依赖关系的特征函数,$\lambda_m$是特征函数的权值。最大熵马尔科夫模型和条件随机场的根本区别在于公式中的归一化项$Z$的不同。对于最大熵马尔科夫模型, $$Z = \prod_{n=1}^N \sum_{\tilde{s}} exp(\sum_1^M \lambda_m h_m(s_{n-1}, \tilde{s}, w_1^N))$$ 其中$\tilde{s}$表示所有可能的语义槽标签。而对于条件随机场, $$Z = \sum_{\tilde{s}_1^N} \prod_{n=1}^N exp(\sum_1^M \lambda_m h_m(\tilde{s}_{n-1}, \tilde{s}_n, w_1^N))$$ 其中$\tilde{s}_1^N$表示所有可能的输出序列。这两个模型的根本区别在于MEMM仅做了局部的归一化,并没有考虑所有可能的输出序列再做归一化,MEMM会产生著名的标签偏移(label bias)问题(Lafferty et al. 2001)。目前传统统计模型在ATIS评测集合上取得最好效果的是CRF,语义槽检测的调和平均值(F-score)达到了92.94%(Mesnil et al. 2013)。
通过使用三角CRF(Triangular-CRF),条件随机场的结构也可以经过适当的改变,同时预测一个句子的主题或者说也可以同时做句子分类的任务(Jeong et al. 2008)。
非对齐数据与传统统计模型
基于词对齐数据的口语理解通常被看做一个序列分类问题。即给定词序列(输入句子)$w_1^N=w_1, w_2, …, w_N$,要预测一个语义项集合$c_1^T=c_1, c_2, …, c_T$,$N$是输入序列长度,$T$是语义项集合大小。语义项是一句话的语义表示的子结构,通常包括对话动作类型(或者句子意图)、语义槽值对。
生成式的动态贝叶斯网络在观察到的词的基础上,可以将一句话的语义建模成一个隐式结构(Schwartz et al. 1996; He et al. 2006)。该方法可以使用最大期望算法在非对齐的数据上进行训练,但是马尔科夫假设使得该模型不能准确地对词的长程相关性进行建模。一种分层隐状态的方法(He et al. 2006)可以很好地解决这一问题,但它所需要的计算复杂度很高。另外一种鲁棒的生成式概率语法也可以从非对齐数据中学习得到(Zettlemoyer et al. 2007)(前文小节2.1中也提到了)。Jurcicek等人基于带权值的有限状态传感器(Weighted Finite State Transducer, WFST),采用贪心的策略,提出了可以自动构建文字片段到语义项映射的算法(Jurcicek et al. 2009)。
Mairesse等人在使用支持向量机分类器的基础上提出了语义元组分类器(Semantic Tuple Classifier, STC)的方法(Mairesse et al. 2009),该语义元组分类器是对句子的分类,它可以在非对齐的数据上训练。该方法利用了句子中词的N元组(N-gram)特征,对每一种出现过的语义项训练一个分类器。该方法还采用了类别替换的技巧(比如把“上海”、“北京”替换为CITY)来提升模型的泛化能力。
深度学习方法
近十年来,深度学习技术在人工智能领域的各个领域都取得了突破性的进展,包括语音处理、图像处理、自然语言处理等领域。深度学习技术在各个领域的具体体现就是深度神经网络模型的应用。在自然语言处理领域,特别是循环神经网络(Recurrent Neural Networks, RNN)在语言模型研究中的成功应用(Mikolov et al. 2010; Mikolov et al. 2013),将深度学习方法在自然语言处理中的研究热度推向高峰。
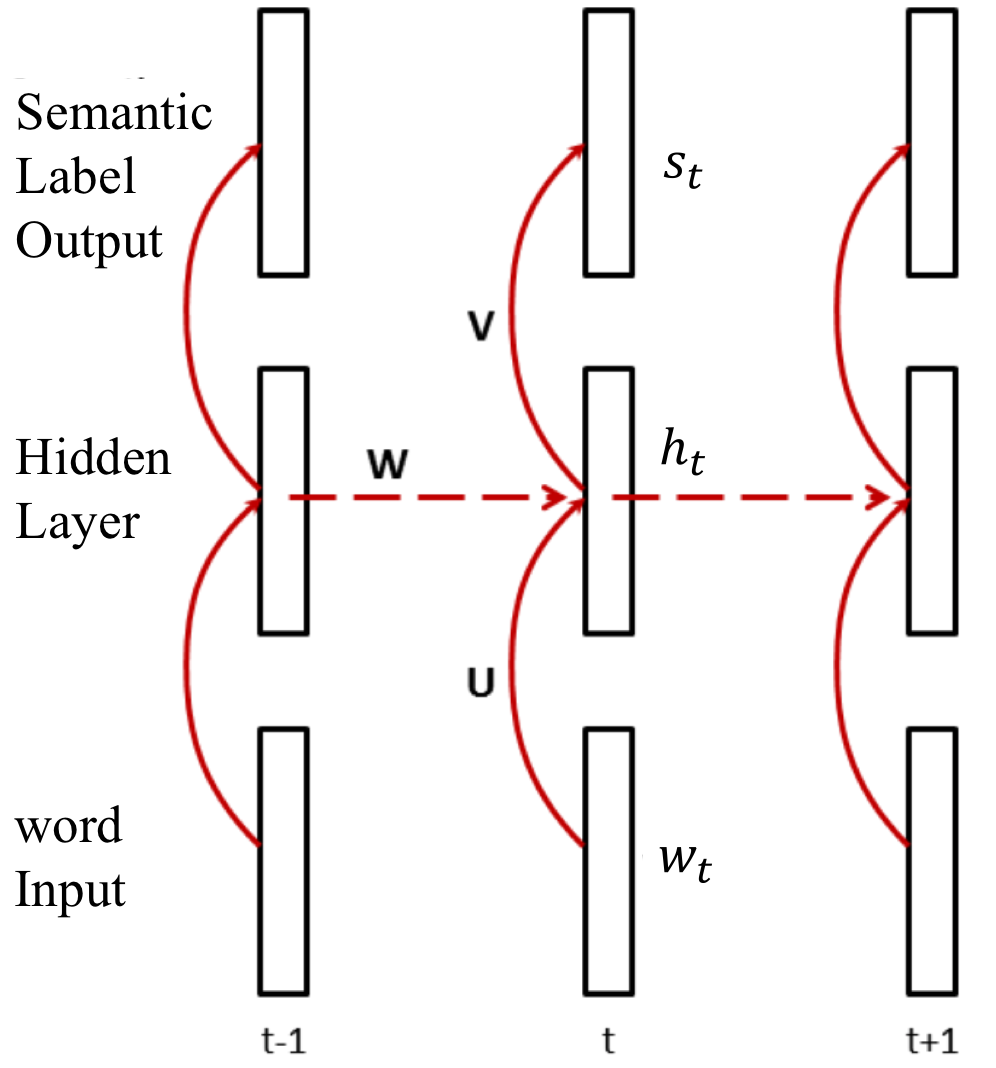
在口语理解的语义槽填充(基于序列标注)任务上,循环神经网络首先取得突破。Yao 和 Mesnil同时将单向RNN应用于语义槽填充任务,并在ATIS评测集合上取得了显著性超越CRF模型的效果(Yao et al. 2013; Mesnil et al. 2013)。如图7所示,这是一个用于口语理解中序列标注任务的循环神经网络模型结构。其中最下一层为输入层,中间为隐层,最上面一层为输出层。每一层都代表了一系列的神经元,层与层之间由一个权值矩阵连接,如图中的$\textbf{U}$,$\textbf{W}$,$\textbf{V}$。输入层$w_t$表示的是输入词序列第$t$时刻词的1-of-K向量(即K为词表大小,向量中$w_t$对应的的那一维值为1,其他值全为0)。输出层向量$s_t$表示的是在语义标签上的概率分布,向量长度是所有可能语义标签的数量。隐层和输出层的计算过程如下:
$$
\begin{align*}
& \textbf{h}_t = f(\textbf{U}\textbf{w}_t + \textbf{W}\textbf{h}_{t-1}) \
& \textbf{s}_t = g(\textbf{V}\textbf{h}_t)
\end{align*}
$$
其中,$f(z)=\frac{1}{1+e^{-z}}$,$g(z_m)=\frac{e^{z_m}}{\sum_k e^{z_k}}$。$f$为sigmoid激活函数(神经网络的激活函数还有很多,比如tanh、ReLU等),$g$为softmax归一化函数。公式中$\textbf{U}\textbf{w}_t$将1-of-K向量(离散)映射为一个连续的向量,该连续向量的词表示常被称为词向量或者词嵌入(word embedding)。
该模型可以使用标准的神经网络反向传播算法优化参数,目标是最大化数据的负的条件对数似然: $$-\sum_tlog(p(\textbf{s}_t|\textbf{w}_1…\textbf{w}_t))$$ 该模型中输出的语义标签是没有相互依赖关系的,且$t$时刻的输出预测仅依赖于当前词和它的历史词序列。此外,为了看到一定的将来词信息,可以以当前词为中心,设置一个固定大小的输入窗口(比如$2d+1$个词),则$t$时刻的输入从$w_t$变为$w_{t-d}^{t+d}$,这样做的效果会有一定的提升。
然而这种简单的循环神经网络不容易训练,存在梯度消失(gradient vanishing)或者梯度爆炸(gradient exploding)的问题。长短时记忆单元(Long Short-term Memory, LSTM)的提出(Hochreiter 1998; Graves 2012)则有效解决了这两个问题,LSTM的公式描述如下:
$$
\begin{align*}
\textbf{i}_t &= \sigma(\textbf{W}^{(xi)}\textbf{x}_t + \textbf{W}^{(hi)}\textbf{h}_{t-1} + \textbf{W}^{(ci)}\textbf{c}_{t-1} + \textbf{b}^{(i)})\\
\textbf{f}_t &= \sigma(\textbf{W}^{(xf)}\textbf{x}_t + \textbf{W}^{(hf)}\textbf{h}_{t-1} + \textbf{W}^{(cf)}\textbf{c}_{t-1} + \textbf{b}^{(f)}) \\
\textbf{c}_t &= \textbf{f}_t \bullet \textbf{i}_t + \textbf{i}_t \bullet tanh(\textbf{W}^{(xc)}\textbf{x}_t + \textbf{W}^{(hc)}\textbf{h}_{t-1} + b^{(c)}) \\
\textbf{o}_t &= \sigma(\textbf{W}^{(xo)}\textbf{x}_t + \textbf{W}^{(ho)}\textbf{h}_{t-1} + \textbf{W}^{(co)}\textbf{c}_{t-1} + \textbf{b}^{(o)}) \\
\textbf{h}_t &= \textbf{o}_t \bullet tanh(\textbf{c}_t)
\end{align*}
$$
其中$\textbf{i}_t$、$\textbf{f}_t$、$\textbf{c}_t$、$\textbf{o}_t$和$\textbf{h}_t$分别代表t时刻的输入门、遗忘门、神经元激活、输出门和隐层值的向量。$\sigma(.)$是sigmoid函数。$\textbf{W}$是连接不同门的权重矩阵,$\textbf{b}$是对应的偏差向量,只有$\textbf{W}^{(ci)}$、$\textbf{W}^{(cf)}$、 $\textbf{W}^{(co)}$是对角矩阵。从功能角度而言,上述公式中的输入向量$\textbf{x}_t$和隐层向量$\textbf{h}_t$与传统RNN的输入和隐层值是一致的。Yao等人第一次将基于LSTM的循环神经网络应用于口语理解领域(Yao et al. 2014),并在ATIS任务上取得了优于传统RNN的性能。但是LSTM的计算复杂,一些更简单的门控单元也被提出和使用,比如门控循环单元(Gated Recurrent Units,GRU)(Chung et al. 2015; Vukotic et al. 2016)。
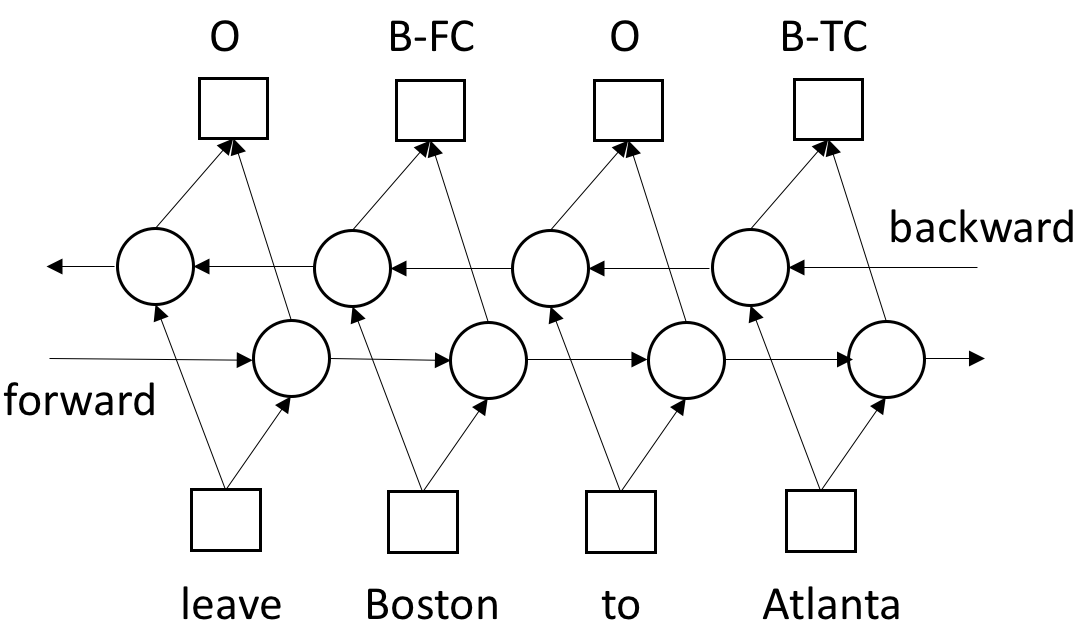
以上是单向循环神经网络的模型,只能考虑当前时刻的历史信息,而不能考虑将来词的信息。由于口语理解一般是给定一句完整的话,预测语义信息,所以我们可以同时考虑历史词和将来词的信息。最典型的就是双向循环神经网络模型,该模型是由两个单向循环神经网络组成,一个向右传播(forward),一个向左传播(backward),如图8所示。双向循环神经网络模型在ATIS任务上也取得了比单向循环网络更好的性能(Vu et al. 2016; Zhu et al. 2016)。基于双向循环神经网络模型的语义标签序列标注可以表示为如下条件概率公式: $$p(s_1^T|w_1^T) = \prod_{t=1}^T p(s_t|w_1…w_T) = \prod_{t=1}^T p(s_t|w_1^T)$$ 其中$w_1^T$、$s_1^T$分别表示输入、输出序列,$s_t$表示$t$时刻的语义标签。
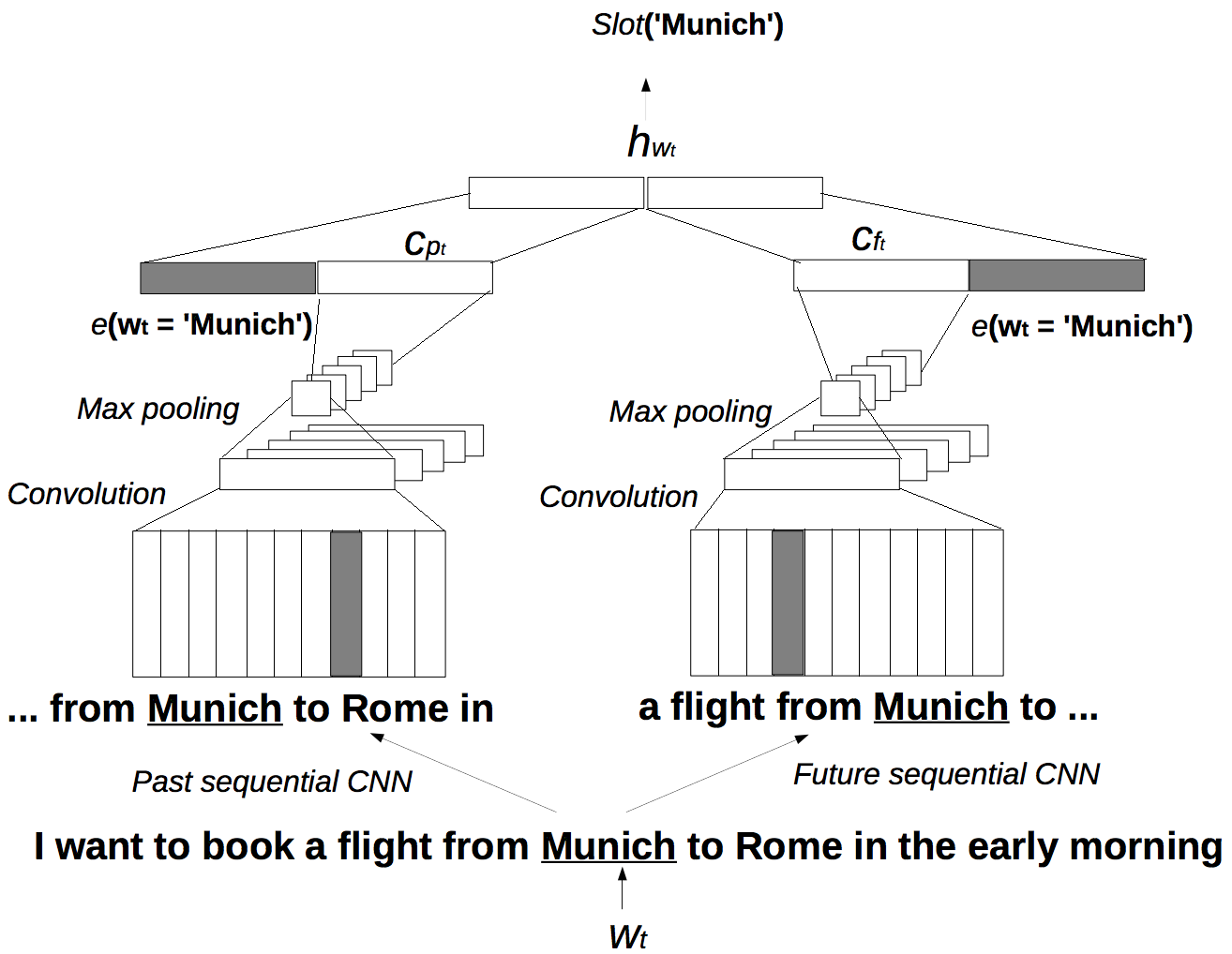
除了循环神经网络,卷积神经网络(Convolutional Neural Networks, CNN)也经常被应用到序列标注任务中(Xu et al. 2013; Vu 2016),因为卷积神经网络也可以处理变长的输入序列。如图9所示,这是一个比较成功的CNN在口语理解中的应用。该模型对$t$时刻的词$w_t$进行特征提取,得到$h_{w_t}$,最后加一个前馈神经网络,预测$w_t$的语义标签$slot(w_t)$。CNN模型的应用在于如何自动提取$w_t$在当前句子中的上下文特征。该模型中使用CNN分别对当前上下文的历史信息和将来信息分别提取特征。其历史信息为句子的第一个词一直到第$t+d$个词,其中d表示局部的窗口大小(在图中d=3),而将来信息则是第$t-d$个词直到句子的末尾。CNN模型的权值矩阵在这两个词序列上以一定窗口大小移动,将词向量特征做一次线性变换,并通过非线性的激活函数(sigmoid、ReLU等)得到隐层信息。最大值池化(Max pooling)操作将CNN卷积操作后的变长隐层信息转化为固定长的向量(如图中的$C_{p_t}$,$C_{f_t}$)。在得到上下文信息$C_{p_t}$、$C_{f_t}$后,该模型最后又将当前词的词向量信息$e(w_t)$合并进来,并加入一层前馈神经网络,组成最后完整的特征$h_{w_t}=[(U\cdot e(w_t), V_p \cdot C_{p_t}), (U\cdot e(w_t), V_f \cdot C_{f_t})]$。
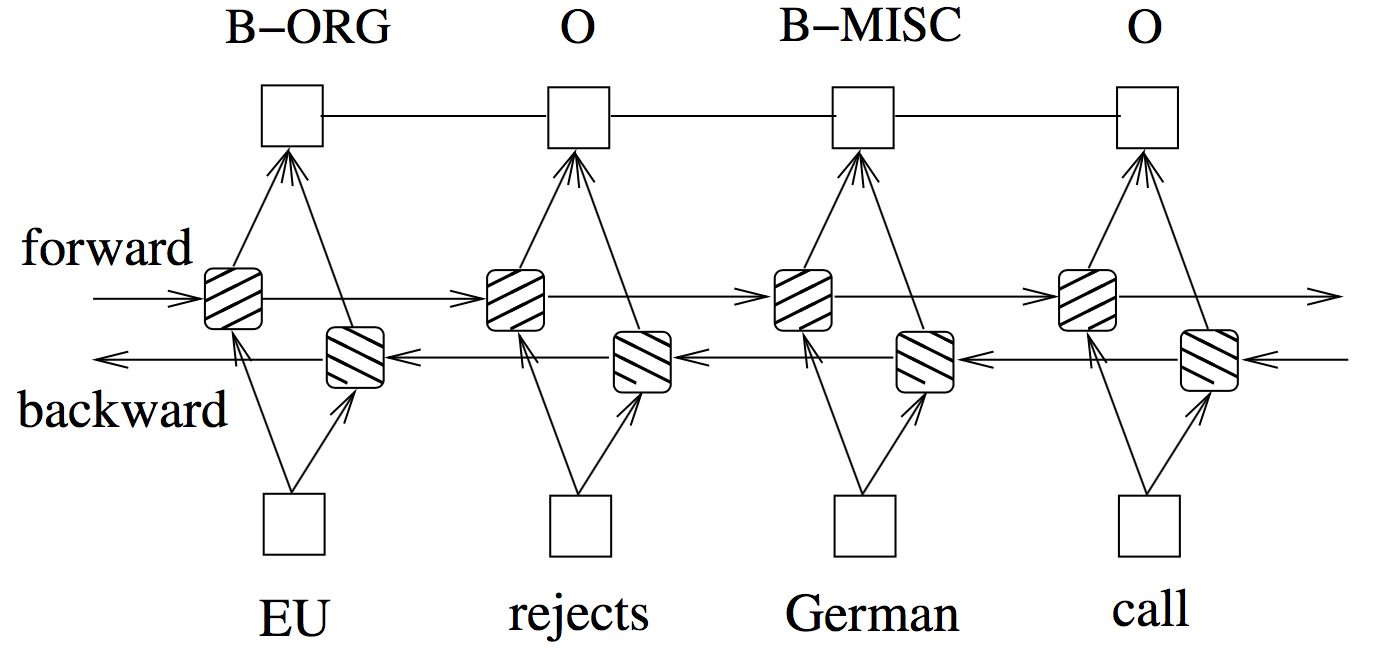
上述模型在建模中输出序列上不同时刻的预测是相互独立的,没有考虑输出结果直接的依赖关系。而传统模型条件随机场(CRF)则对相邻输出直接的依赖关系有较好的建模,于是诸多研究者将深度神经网络(RNN、LSTM、CNN等)与CRF相结合(Yao et al. 2014; Xu et al. 2013; Huang et al. 2015)。这类模型的核心在于将深度神经网络看成一个很强的序列特征提取模型,并将这些特征及其值看作为CRF模型的特征函数和相应的权值(或者将CRF优化目标函数看作深度神经网络的优化目标),如图10所示。由于CRF模型也可以采用反向传播的算法更新参数,于是这样一个结合的模型可以联合优化。
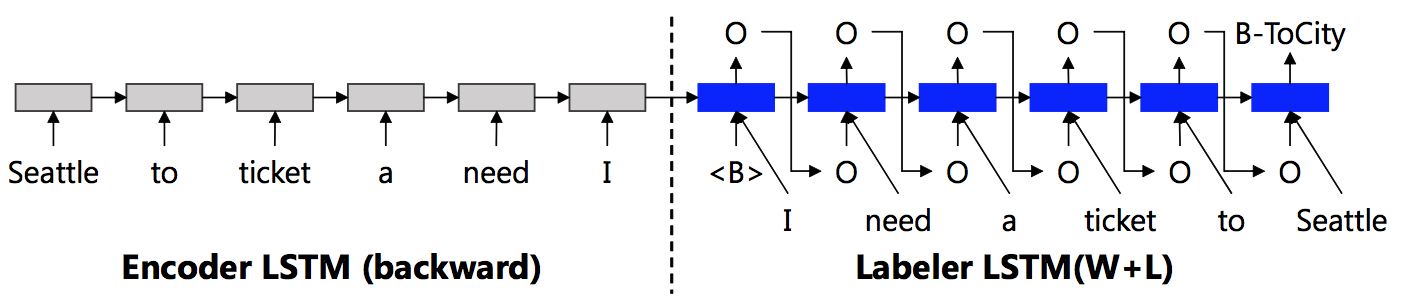
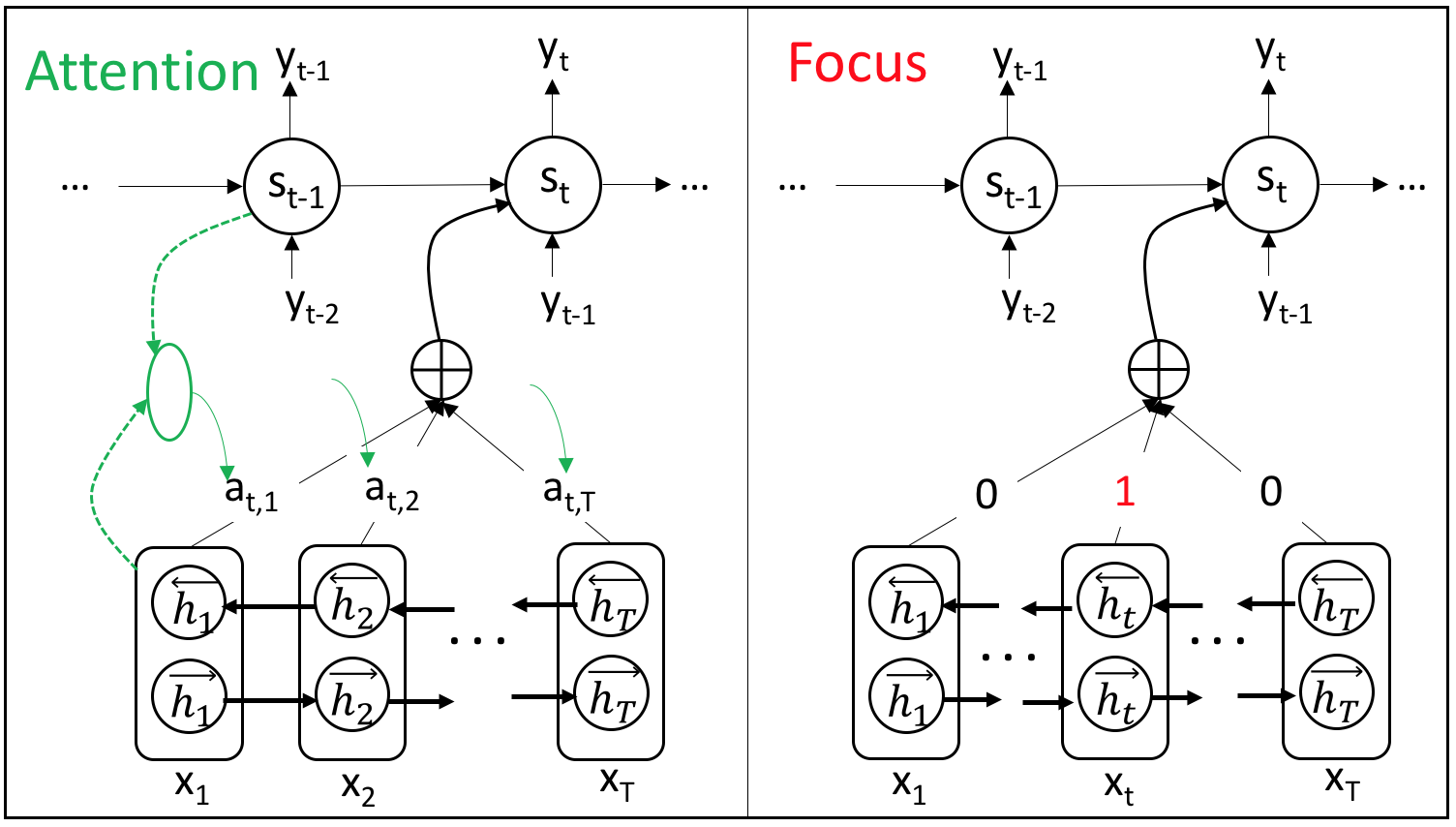
除了与传统CRF模型的结合,基于序列到序列(sequence-to-sequence)的编码-解码(encoder-decoder)模型(Bahdanau et al. 2014)也被应用到口语理解中来(Simonnet et al. 2015)。这类模型的encoder和decoder分别是一个循环神经网络,encoder对输入序列进行编码(特征提取),decoder根据encoder的信息进行输出序列的预测。其核心在于decoder中$t$时刻的预测会利用到$t-1$时刻的预测结果作为输入。则应用此模型的语义标签序列标注可以表示为如下条件概率公式: $$p(s_1^T|w_1^T) = \prod_{t=1}^T p(s_t|w_1^T;s_1…s_{t-1})$$ 其中$w_1^T$、$s_1^T$分别表示输入、输出序列,$s_t$表示$t$时刻的语义标签。受encoder-decoder模型的启发,Kurata等人提出了编码-标注(encoder-labeler)的模型(Kurata et al. 2016),其中encoder RNN是对输入序列的逆序编码,decoder RNN的输入不仅有当前输入词,还有上一时刻的预测得到的语义标签,如图11所示。Zhu (Zhu et al. 2016)和Liu (Liu et al. 2016)等人分别将基于关注机(attention)的encoder-decoder模型应用于口语理解,并提出了基于“聚焦机”(focus)的encoder-decoder模型,如图12所示。其中attention模型(Bahdanau et al. 2014)利用decoder RNN中的上一时刻$t-1$的隐层向量和encoder RNN中每一时刻的隐层向量依次计算一个权值$\alpha_{t,i}, i=1,…,T$,再对encoder RNN中的隐层向量做加权和得到$t$时刻的decoder RNN的输入。而focus模型则利用了序列标注中输入序列与输出序列等长、对齐的特性,decoder RNN在$t$时刻的输入就是encoder RNN在$t$时刻的隐层向量。(Zhu et al. 2016; Liu et al. 2016)中的实验表明focus模型的结果明显优于attention,且同时优于不考虑输出依赖关系的双向循环神经网络模型。目前在ATIS评测集合上,对于单个语义标签标注任务且仅利用原始文本特征的已发表最好结果是95.79%(F-score)。
此外,许多循环神经网络的变形也在口语理解中进行了尝试和应用,比如:加入了外部记忆单元(External Memory)的循环神经网络可以提升网络的记忆能力(Peng et al. 2015)。
口语理解中的不确定性建模
如小节1.3所述,自然口语对话系统中的语音识别难以避免错误,且其规律性也很难发现。这就使 得语音通道的输入具有非精确性。传统的优化观点认为,提升识别准确率,减低非精确性是实现有效口语理解的唯一途径。然而,从认知技术的角度去 看,人类语言自身就具有高度的模糊性,认知科学的观点认为,允许使用模糊的表达手段可以避免不必要的认知负担,有利于提高交互活动的高效性和 自然度。允许非精确输入,将使得信息的输入带宽大大提高,人机交互的自然性和高效性极大改观。因此,如何在非精确条件下实现有效的理解,即认知统计口语理解,是认知技术的重要研究范畴。
认知统计口语理解就是从非精确的编码输入中,得到准确的最优或多重语义理解。它和传统自然语言处理不同之处在于,可能存在多重通道的编码以准同步的方式输入,输入编码本身可能存 在与用户意图无关的编码错误,且对应同一输入信号,通道层可能输出多种编码解释。多种编码解释是由于信息从输入通道中传输而产生的不确定性,这些不确定性与通道自身的性质或对话情境有关。 保留合理的多重编码解释或利用多通道的非精确输入会为用户意图的理解和后续决策提供更多的信息,因而认知型统计口语理解范畴下,具有不确定性的输入通道的多重编码解释技术就成为重要的一环。
多重编码及置信度代表了输入不确定性,其表达形式可以有很多种,如前文小节1.3介绍的N最佳假设列表(N-best hypotheses list)、词格(word lattice)和词混淆网络(word confusion network)。
口语理解模型需要对此类包含不确定性信息的输入进行建模,来提升模型对于不确定信息以及语音识别错误的鲁棒性。一种非常简单易行的方法(Henderson et al. 2012):1)模型训练阶段,使用用户所说话的人工转写文本(即完全正确的词序列)或者语音识别输出的top hypothesis(即预测结果中置信度最高的词序列)以及语义标注进行口语理解模型训练;2)模型测试阶段,使用语音识别输出结果的N-best句子列表,将1至N句话一一输入模型进行语义解析,最后联合考虑语音识别结果的置信度和语义解析的置信度将语义解析结果进行整合(Merge duplicates)。其过程如图13所示,
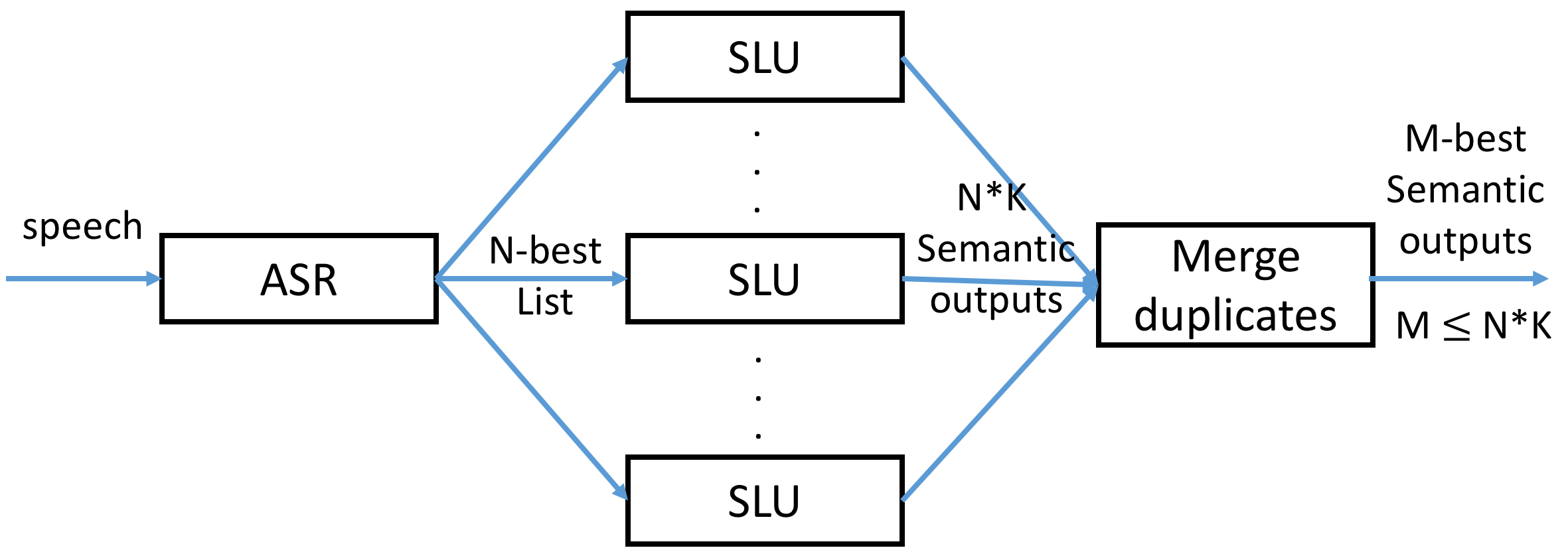
早期口语理解中的不确定性建模训练都是基于语音识别结果中置信度最高的词序列(即ASR 1-best结果)(He et al. 2006; Mairesse et al. 2009),但是显然N最佳假设列表(N-best hypotheses list)、词格(word lattice)和词混淆网络(word confusion network)等语音识别输出编码包含的信息量更大、置信度更准确。后续相继有人在N最佳假设列表、词格、词混淆网络上提取口语理解的特征,进行不确定性建模(Hakkani et al. 2006; Henderson et al. 2012; Tur et al. 2013; Yang et al. 2015)。
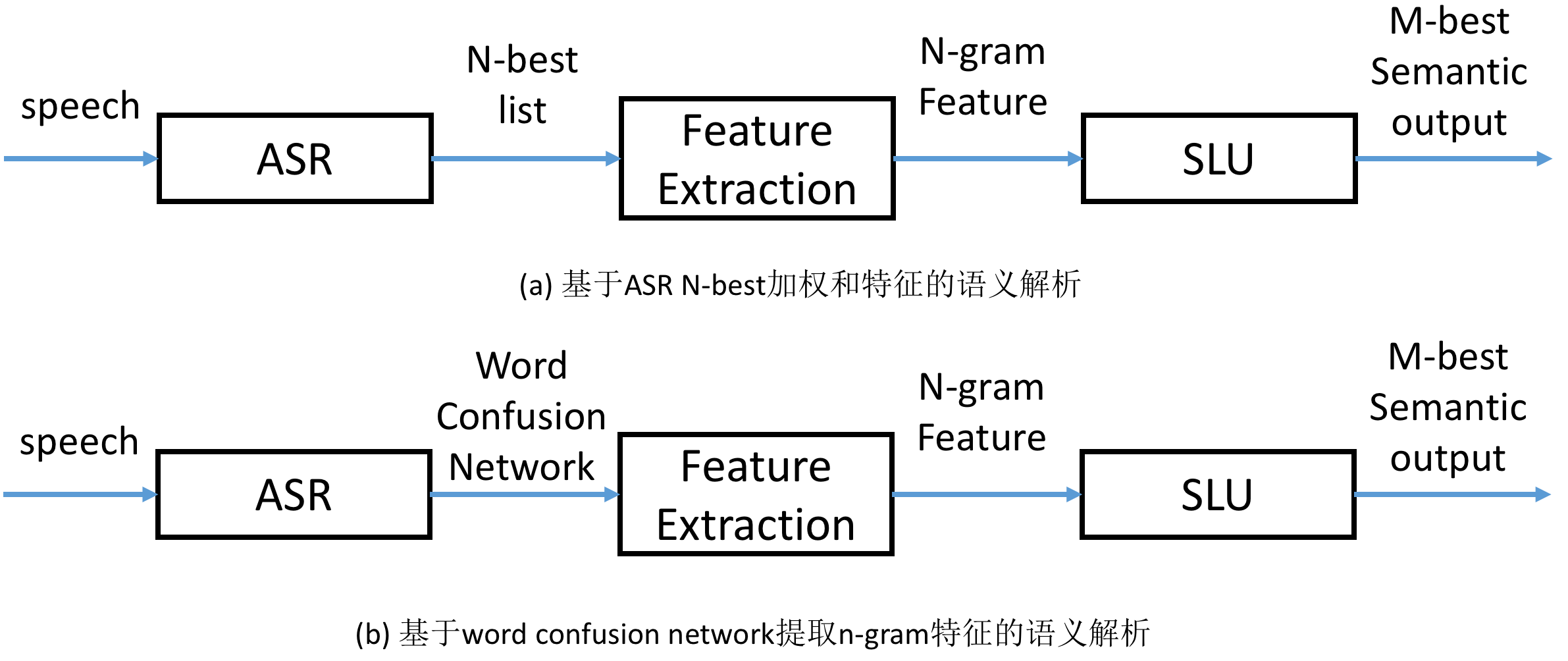
基于非对齐数据的口语理解(在前文中有提及,小节2.2.1),Henderson等人直接对N-best hypotheses list以及word confusion network提取特征,利用支持向量机模型构建语义元组分类器(semantic tuple classifiers),进行语义解析器的训练和测试(Henderson et al. 2012)。该方法的核心思想就是将ASR最有可能的前N句输出的n-gram特征做加权和(权值依据它们各自在ASR中的后验概率)。这样即综合了ASR N-best输出的信息,又减少了解析回合数(因为一般基于1-best n-gram训练的模型在解析N-best输入时,需要重复运行N遍,比如图13中的方法),如图14(a)所示。
ASR N-best的n-gram特征定义如下: $$x_i = \mathop{\sum_{j=1}^N} C_{hyp_j}(n\text{-}gram_i)*p_j$$ 其中$x_i$是第$i$个n-gram的值,即是最终n-gram特征向量中第$i$维的值;$hyp_j$是ASR输出N-best列表的第$j$个句子,$p_j$则是它的后验概率;函数$C_u(ng)$表示n元组$ng$在句子$u$中出现的次数。
类似地,该方法中word confusion network的n-gram特征定义如下: $$x_i = E(C_{u}(n\text{-}gram_i))^{1/|n\text{-}gram_i|}$$ 其中$|n\text{-}gram_i|$表示$n\text{-}gram_i$中词的个数。$E(C_{u}(n\text{-}gram_i))$表示的是$n\text{-}gram_i$在word confusion network中出现的次数的期望(即$n\text{-}gram_i$出现的概率之和)。公式中的指数项是一个归一化操作,因为越长的n—gram的出现次数期望越低。论文(Henderson et al. 2012)中的结果也显示使用ASR N-best的n-gram特征可以取得比只利用ASR 1-best的更好的性能,而利用了word confusion network的n-gram特征的方法可以取得最好的结果。因为从保护的信息量的角度来说,word confusion network大于ASR N-best,ASR N-best大于ASR 1-best。
除了非对齐数据,在面向对齐数据的口语理解(一般被定义为序列标注问题)中,词混淆网络也被利用进来。Tur等人将词混淆网络看做一个分段序列(Bin),其中每一个分段代表的音频中相邻两个时刻可能对应的所有词及其后验概率,这样传统序列标注的模型(比如CRF)就可以应用上了(Tur et al. 2013)。该方法的第一步是将输出序列的语义标签与词混淆网络分段进行对齐,如图15所示,每一个分段(Bin)中包含了该时间段内所有可能的词。该方法中基于CRF建模,对相邻的分段提取n-gram特征。实验证明基于词混淆网络的模型的性能优于只是用了ASR 1-best的模型。但该方法在训练过程中没有考虑词混淆网络中每个词的后验概率。(Yang et al. 2015)则在该方法的基础上做了两点改进:1)考虑了分段(Bin)中每个词的后验概率,对分段进行聚类,构建基于分段类别的词表;2)在分段类别的序列上引入循环神经网络和CRF结合的模型。该方法进一步取得了口语理解性能的提升,并再一次验证了口语理解不确定性建模的优势。

上下文建模及领域自适应
基于对话上下文的口语理解
在口语对话框架下,口语理解往往是对上下文敏感的,即同样的一句话在不同的对话情境下语义会不一样。比如下面这两个情景下的例子:
- 用户轮次 1: “请帮我订一张去北京的机票”
- 用户轮次 2:“明天上午10点”
- 用户轮次 1:“帮我设定一个时间提醒”
- 用户轮次 2:“明天上午10点” 从例子中可以看出,前后两次“明天上午10点”的意义是不一样的,前一个是指机票的出发时间,后一个是指设置提醒的时间。在很多时候,单独一句话是会引发歧义的,而对话上下文的引入则可以在一定程度上解决这一类的语义歧义现象。
在口语人机对话框架下主要有两类上下文信息,一类是用户以前说过的话(如上面的例子),一类则是机器以前说过的话(一般在对话系统内部以语义表示的形式存在)。这两类上下文信息的使用都可以对用户的口语理解提供帮助。
Henderson等人利用机器最新的回复信息(语义表示形式)作为语义解析器的额外特征来提升口语理解性能(Henderson et al. 2012)。该方法首先获取机器内部最新的回复信息的语义表示(比如对话动作类型、意图类别、语义槽值对),将它们的出现与否当做额外特征,与原始的文本特征一起辅助口语理解模型的训练和测试。该论文中的实验表明机器端的历史信息对于口语理解的帮助非常大。
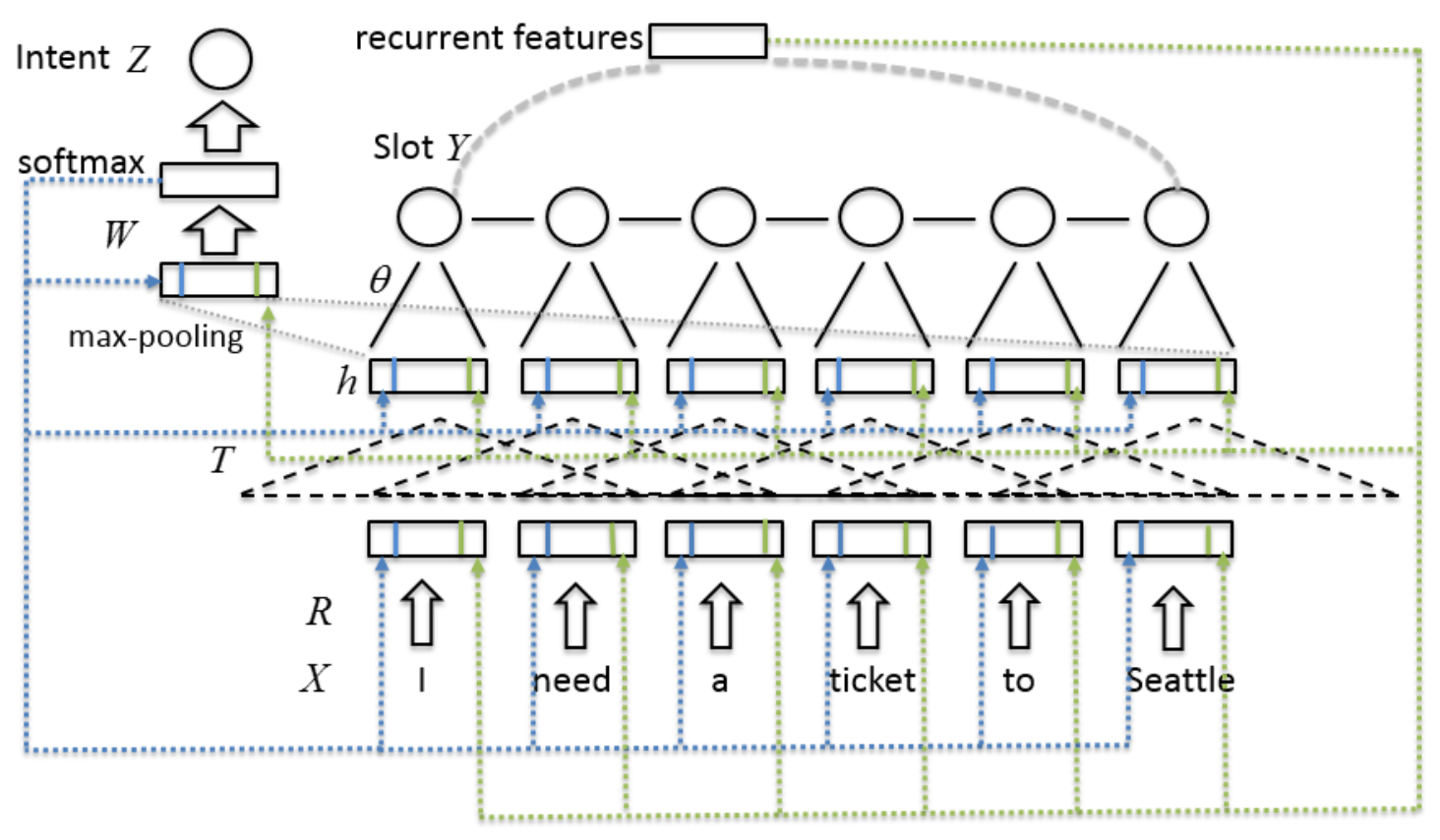
Liu等人采用循环神经网络的思想,利用一个循环层记录口语理解模型的历史信息(Liu et al. 2015)。如图16所示,如果不考虑带箭头的虚线,剩下的模型是基于CNN和CRF相结合的口语理解模型(Xu et al. 2013)。而带箭头的虚线分两种,表示不同的历史信息的引入方式:蓝色的线表示模型中循环连接的部分,包括输入层和隐层,在实际训练中需要展开;绿色的线表示上一轮次的用户的语义解析结果(Recurrent features),被当做当前轮的额外历史特征。
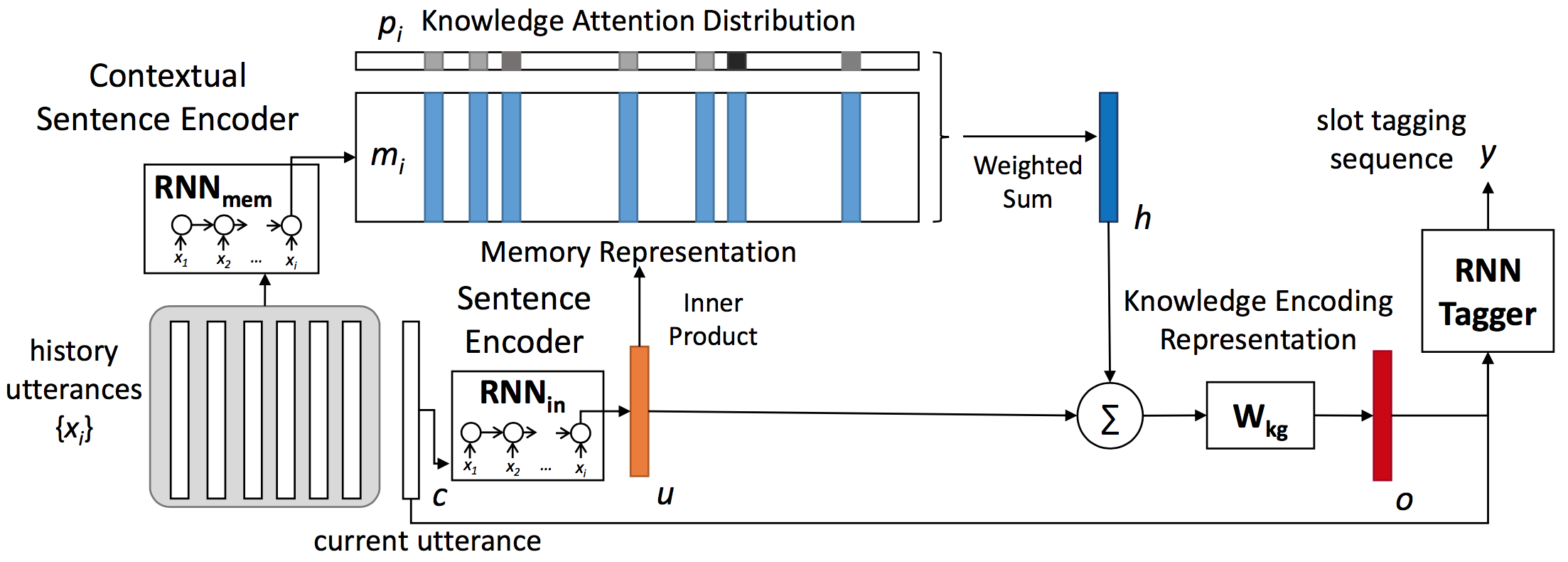
Chen等人提出利用记忆网络(Memory Network)来将历史上下文编码为一种知识表示向量,再利用该向量作为当前句子口语理解的额外特征,在多轮对话任务上相对于不对上下文建模的方法有了很大提升(Chen et al. 2016)。如图17所示,该框架包含三个RNN模型,分别是对历史句子进行编码的$RNN_{mem}$、对当前句子进行编码的$RNN_{in}$、进行口语理解-序列标注的RNN Tagger。其中$RNN_{mem}$将历史句子${x_i}$分别编码为一个向量(如图所示,为RNN的最后一个时刻的隐层向量),同样$RNN_{in}$把当前句子$c$也编码为一个向量。
$$
\begin{align*}
m_i &= RNN_{mem}(x_i) \\
u &= RNN_{in}(c)
\end{align*}
$$
这样历史句子集合${x_i}$就被转换为一个知识向量集合${m_i}$,下一步是利用当前句子的向量表示和知识向量集合计算一个知识关注(attention)分布${p_i}$:
$$p_i = softmax(u^T m_i)$$
其中$softmax(z_i)=e^{z_i}/\sum_je^{z_j}$,$p_i$可以看做是当前句子和历史句子的相关度。
最后我们获得知识编码表示向量:
$$
\begin{align*}
h &= \sum_i p_i m_i \\
o &= W_{kg}(h+u)
\end{align*}
$$
其中$W_{kg}$是一个线性变换矩阵,$o$为最终的知识编码向量。该知识编码向量可以作为口语理解-序列标注模型的额外特征,使用历史句子信息对当前句子的口语理解进行去歧义化的帮助。由于整个框架之间的模型连接都是平滑可导的,所以所有模型都可以通过标准的反向传播算法进行联合的参数更新。
口语理解中的领域自适应与扩展
基于统计学习(包括深度学习)的口语理解,如果想要在某个对话领域内达到比较好的语义解析效果,足量且准确的数据必不可少。然而实际中获取真实数据十分费时费力,数据标注成本很高。为了实现非限定领域的口语理解,需要研究语义的进化,即语义在不同领域的扩展和迁移。从语义进化的角度看,在传统技术框架下,如果想要扩展口语理解领域,往往需要从头定义领域、收集数据、标注数据和构建系统。于是充分利用已有的资源进行领域自适应的口语理解研究变得尤为重要,且具有很高的实用价值。
多领域的领域自适应
前文提到口语对话领域的数据非常难获取,那么如何利用不同领域的少量数据互帮互助进而提升各自领域的口语理解性能的问题(即领域自适应)变得非常有价值。一种常见的领域自适应方式是对不同领域的数据进行多任务学习,即共享不同领域数据的特征学习层。Jaech等人在基于双向循环网络的口语理解模型上,利用多任务的框架对不同领域的数据进行共享学习(Jaech et al. 2016)。该方法共享双向循环网络的输入层和隐层结构(特征学习相关),而每个领域有一个自己的输出层(任务相关)。实验结果表明多任务学习的框架可以通过共享特征学习来节省不同领域的训练数据量。
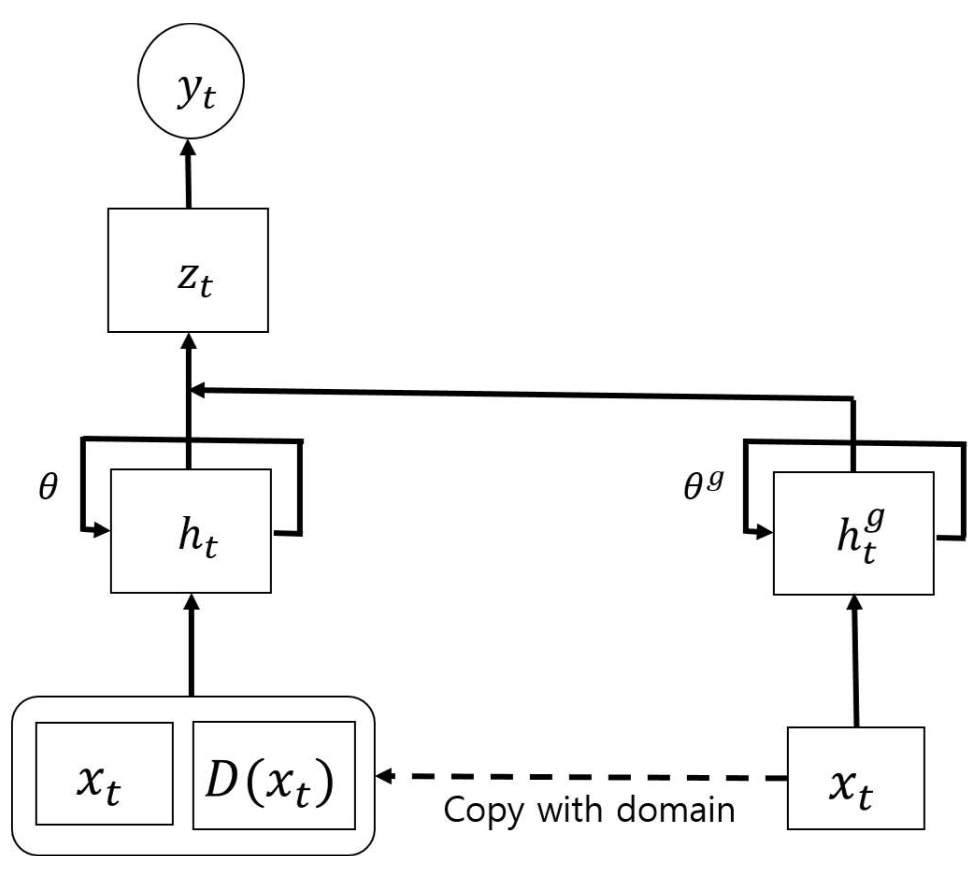
但不同领域之间的特征学习真的是完全可以共享的吗?比如两个很不相关的领域,一个是“音乐播放”,一个是“地点导航”,完全共享是否会对各自领域的口语理解有害。这是一个值得研究的问题。Kim等人就在口语理解任务上对多领域数据的多任务学习框架进行了改进,采用了不同领域直接既有私有参数也有共享参数的方式(Kim et al. 2016)。如图18所示,每一个领域$d$的口语理解模型都分为两部分,左边从$x_t, D(x_t)$到$h_t$再到$z_t$、$y_t$的是领域$d$私有的模型结构,而右边$x_t$到$h_t^g$是领域共享的模型,其中$x_t$是领域共享的词向量,$h_t$表示领域私有的循环神经网络的隐层向量,$h_t^g$则表示领域共有的循环神经网络的隐层向量。由此可见,该模型可以将不同领域之间共享的特征学习模式和领域特有的特征学习模式区分开,进行更好的建模。
领域扩展
当对话领域转移或者扩展的情况下,很难在短时间内获取一定量的数据,这种情况下,基于多任务学习的领域自适应已经不适用或者收效甚微。而更好的方式是研究:如何快速构建扩展领域的数据,或者从其他领域迁移口语理解模式。
Zhu等人提出利用源领域的数据样本模板和目标领域的本体(ontology,包含目标领域的语义槽和语义槽可取的值)自动生成目标领域的数据(Zhu et al. 2014),其中获取源领域的数据样本模板的过程是加入了人工规则的。该方法对不同对话领域之间的语义数据进行了分类:
- 领域无关型:有一类数据是领域无关的或者是通用的,比如常见的“你好”、“再见”等通用语句。
- 领域可转让型:有一类数据是两个领域共有的,但并不是所有领域都会有,比如“订机票”和“订火车票”领域都会有价格查询的数据。
- 领域限制型:这一类数据对于某一个领域的特有的,不可以直接被其他领域转移使用。
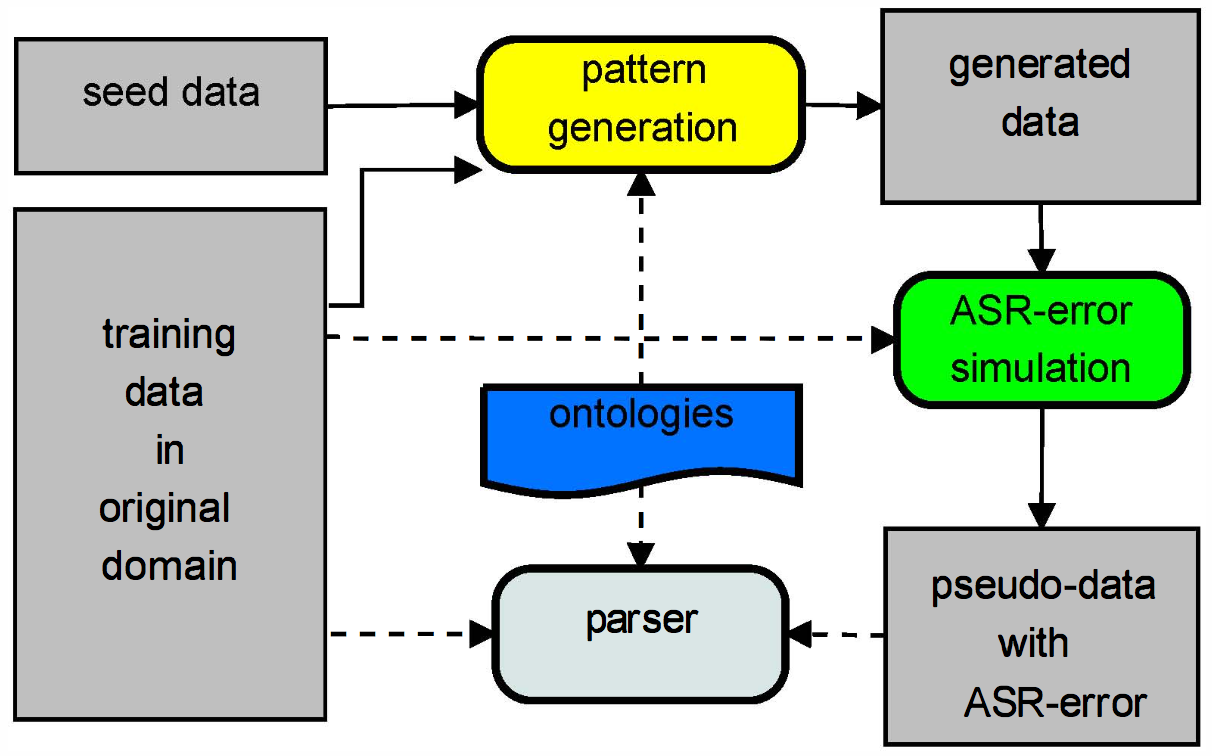
Zhu等人提出提出来的数据模拟生成就是主要解决第三类的数据迁移问题。如图19所示,该口语理解的数据模拟生成方法包括五部分: 1. 源领域的数据样本模板提取。该过程通过人工规则提出源领域数据中语义槽值部分,获取抽象化的句子模板及其语义标注。比如:句子模板为“I need moderately priced [food] food”,语义标注为“inform(pricerange=moderate,food=[food])”,其中$[food]$表示该位置可以填入任何的food相关的值。 2. 目标领域的样本模板生成(pattern generation)。该过程通过读取模板领域的本体(ontology)中的语义槽信息,将源领域模板中的抽象化语义槽替换为目标领域中新出现的语义槽。 3. 根据新生成的样本模板,以及本体中记录的每一种语义槽可能对应的值,进行槽值填充,生成目标领域的文本数据(generated data)。 4. 语音识别错误模拟(ASR-error simulation)。为了提高口语理解对于语音识别错误的鲁棒性,该方法还利用了源领域的数据构建词混淆矩阵,以一定概率将正确的词映射为错误的词。 5. 目标领域的口语理解模型训练。
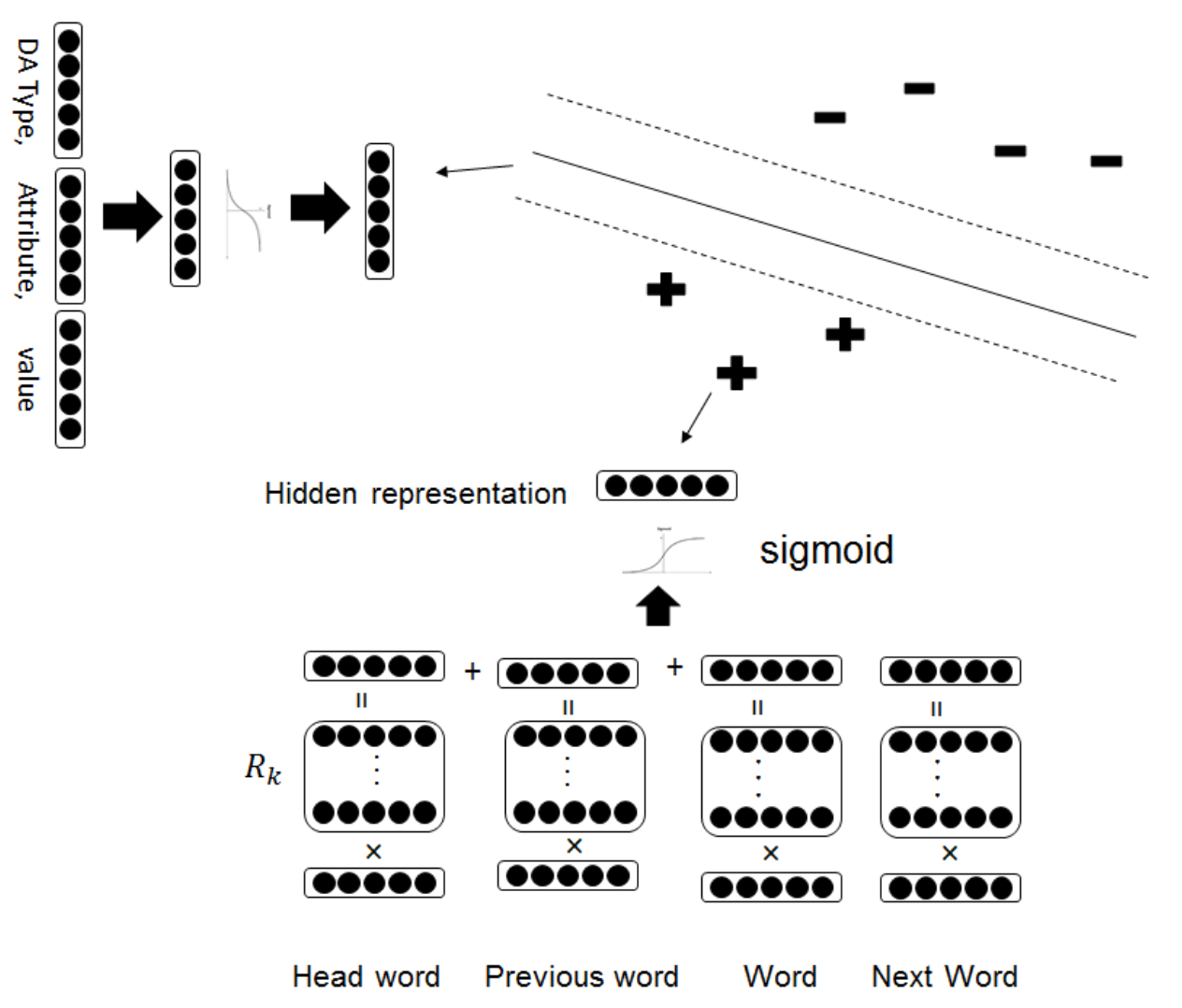
除了传统的数据生成的方式,零数据样本的学习策略(zero-shot learning)也被应用到口语理解中来(Yazdani et al. 2015; Ferreira et al. 2015; Ferreira et al. 2015)。其中Ferreira等人利用预训练的词向量(比如word2vec、GLOVE等工具的公开资源)和词向量相似度计算,进行输入句子和语义项的匹配(匹配过程可以是无参数的)(Ferreira et al. 2015; Ferreira et al. 2015)。该方法是一种不错的冷启动方式,但过度依赖预训练的词向量,且词向量相似度对于专有领域的语义不一定可靠,比如“是”和“否”两个词在词向量空间很接近,但语义却是反的。Yazdani等人基于非对齐的口语理解任务提出了一种迁移学习的框架(Yazdani et al. 2015),该模型框架将传统基于句子特征输入的语义项分类器改变为同时输入句子特征和语义项特征的相似度计算二分类器,如图20所示。核心在于传统的语义项分类模型中,语义项类别之间是相对独立的,而该模型框架语义项类别直接不相互独立。从统计模型分类的角度,传统语义项分类模型是判别式模型$p(y|x)$(其中$x$为句子输入,$y$为语义项类别),而该模型框架是生成式模型$p(x,y)$。从而,对于领域扩展后出现的新的语义项$y’$,判别式模型$p(y|x)$无法预测,而生成式模型$p(x,y)$还可以直接计算。
另外,Chen等人借助外部开放语义资源(FrameNet)以及知识库(FreeBase)进行了无监督的口语语义理解研究(Chen et al. 2013; Chen et al. 2014; Chen et al. 2015),但该方法要求外部开放语义资源具有完备的领域定义,便捷性不高。Heck等人利用从网页中提取的语义知识图谱对语义项构建自然文本表示,从而生成口语理解的训练数据(Heck et al. 2012)。
尚未解决的问题
语义表示的设计
如何将一个句子的意思表示成合适的结构化形式使其助于鲁棒的语义解析与推理、增加领域之间的可迁移性,将一直是口语理解中最有挑战性的问题。因为语义表示需要满足于各种各样不同的口语对话应用和场景,比如呼叫中心、信息获取、业务导向的应用、娱乐、游戏等等。如果人所说的自然语言是一种信息的源编码,那么语义表示则是目标编码,口语理解就是解码过程。源编码是既定的,那么目标编码的设计也将影响口语理解的算法设计和性能。
语义解析和语音识别的联合优化
如小节1.1.3所述,自然口语对话系统中的语音识别难以避免错误,且其规律性也很难发现。无论如何基于语音识别的输出编码进行不确定性建模,两个模块直接的错误传递总是存在的。为了缩小这种错误传递,对两个模块进行联合优化(或者是端到端的口语理解)是一个很好的解决思路。但由于工程难度和方法难度等原因,目前极少有工作在该研究方向上进行尝试。
口语理解的领域迁移技术
如前文所述,口语理解中的数据收集和标注非常难,且随着用户对口语对话领域的需求的增加,利用已有资源对话口语理解算法进行快速的领域扩展和迁移的研究变得非常重要。目前的领域迁移算法需要完整的领域定义,且要求源领域与目标领域之间有很多的相关性。
参考文献:
[wang2005spoken]: Ye-Yi Wang, Li~Deng, and Alex Acero. Spoken language understanding. IEEE Signal Processing Magazine, 22(5):16–31, 2005.
[hemphill1990atis]: Charles~T Hemphill, John~J Godfrey, George~R Doddington, et~al. The atis spoken language systems pilot corpus. In Proceedings of the DARPA speech and natural language workshop, pages 96–101, 1990.
[dahl1994expanding]: Deborah~A Dahl, Madeleine Bates, Michael Brown, William Fisher, Kate Hunicke-Smith, David Pallett, Christine Pao, Alexander Rudnicky, and Elizabeth Shriberg. Expanding the scope of the atis task: The atis-3 corpus. In Proceedings of the workshop on Human Language Technology, pages 43–48. Association for Computational Linguistics, 1994.
[traum-springer1999]: David~R Traum. Speech acts for dialogue agents. In Foundations of rational agency, pages 169–201. Springer, 1999.
[young2007cued]: Steve Young. Cued standard dialogue acts. Report, Cambridge University Engineering Department, 14th October, 2007, 2007.
[thomson-springer2013]: Blaise Thomson. Statistical methods for spoken dialogue management. Springer, 2013.
[deng2013recent]: Li~Deng, Jinyu Li, Jui-Ting Huang, Kaisheng Yao, Dong Yu, Frank Seide, Michael Seltzer, Geoff Zweig, Xiaodong He, Jason Williams, et~al. Recent advances in deep learning for speech research at microsoft. In Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on, pages 8604–8608. IEEE, 2013.
[bocchieri2013investigating]: Enrico Bocchieri and Dimitrios Dimitriadis. Investigating deep neural network based transforms of robust audio features for lvcsr. In Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on, pages 6709–6713. IEEE, 2013.
[liao2013large]: Hank Liao, Erik McDermott, and Andrew Senior. Large scale deep neural network acoustic modeling with semi-supervised training data for youtube video transcription. In Automatic Speech Recognition and Understanding (ASRU), 2013 IEEE Workshop on, pages 368–373. IEEE, 2013.
[jurafsky2014speech]: Dan Jurafsky and James~H Martin. Speech and language processing. Pearson, 2014.
[murveit1993large]: Hy~Murveit, John Butzberger, Vassilios Digalakis, and Mitch Weintraub. Large-vocabulary dictation using sri’s decipher speech recognition system: Progressive search techniques. In IEEE International Conference on Acoustics, Speech, and Signal Processing, 1993. ICASSP-93, 1993, volume~2, pages 319–322. IEEE, 1993.
[mangu1999finding]: Lidia Mangu, Eric Brill, and Andreas Stolcke. Finding consensus among words: lattice-based word error minimization. In Eurospeech, 1999.
[woods1983language]: William~A Woods. Language processing for speech understanding. Technical report, DTIC Document, 1983.
[price1990evaluation]: Patti Price. Evaluation of spoken language systems: The atis domain. In Proceedings of the Third DARPA Speech and Natural Language Workshop, pages 91–95. Morgan Kaufmann, 1990.
[ward1989understanding]: Wayne Ward. Understanding spontaneous speech. In Proceedings of the workshop on Speech and Natural Language, pages 137–141. Association for Computational Linguistics, 1989.
[ward1994extracting]: Wayne Ward. Extracting information in spontaneous speech. In Third International Conference on Spoken Language Processing, 1994.
[ward1994recent]: Wayne Ward and Sunil Issar. Recent improvements in the cmu spoken language understanding system. In Proceedings of the workshop on Human Language Technology, pages 213–216. Association for Computational Linguistics, 1994.
[seneff1992tina]: Stephanie Seneff. Tina: A natural language system for spoken language applications. Computational linguistics, 18(1):61–86, 1992.
[dowding1993gemini]: John Dowding, Jean~Mark Gawron, Doug Appelt, John Bear, Lynn Cherny, Robert Moore, and Douglas Moran. Gemini: A natural language system for spoken-language understanding. In Proceedings of the 31st annual meeting on Association for Computational Linguistics, pages 54–61. Association for Computational Linguistics, 1993.
[zettlemoyer2007online]: Luke~S Zettlemoyer and Michael Collins. Online learning of relaxed ccg grammars for parsing to logical form. In EMNLP-CoNLL, pages 678–687, 2007.
[hahn2011comparing]: Stefan Hahn, Marco Dinarelli, Christian Raymond, Fabrice Lefevre, Patrick Lehnen, Renato De~Mori, Alessandro Moschitti, Hermann Ney, and Giuseppe Riccardi. Comparing stochastic approaches to spoken language understanding in multiple languages. IEEE Transactions on Audio, Speech, and Language Processing, 19(6):1569–1583, 2011.
[wang2006discriminative]: Ye-Yi Wang and Alex Acero. Discriminative models for spoken language understanding. In INTERSPEECH, 2006.
[raymond2007generative]: Christian Raymond and Giuseppe Riccardi. Generative and discriminative algorithms for spoken language understanding. In Eighth Annual Conference of the International Speech Communication Association, 2007.
[lafferty2001conditional]: John Lafferty, Andrew McCallum, and Fernando~CN Pereira. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. 2001.
[mesnil2013investigation]: Gr{\‘e}goire Mesnil, Xiaodong He, Li~Deng, and Yoshua Bengio. Investigation of recurrent-neural-network architectures and learning methods for spoken language understanding. In INTERSPEECH, pages 3771–3775, 2013.
[jeong2008triangular]: Minwoo Jeong and G~Geunbae~Lee. Triangular-chain conditional random fields. IEEE Transactions on Audio, Speech, and Language Processing, 16(7):1287–1302, 2008.
[schwartz1996language]: Richard Schwartz, Scott Miller, David Stallard, and John Makhoul. Language understanding using hidden understanding models. In Fourth International Conference on Spoken Language, 1996. ICSLP 96. Proceedings, volume~2, pages 997–1000. IEEE, 1996.
[he2006spoken]: Yulan He and Steve Young. Spoken language understanding using the hidden vector state model. Speech Communication, 48(3):262–275, 2006.
[jurcicek2009transformation]: F~Jurc{\i}cek, F~Mairesse, M~Ga{\v{s}}ic, S~Keizer, B~Thomson, K~Yu, and S~Young. Transformation-based learning for semantic parsing. In Proceedings of INTERSPEECH, pages 2719–2722, 2009.
[mairesse2009spoken]: Fran{\c{c}}ois Mairesse, Milica Ga{\v{s}}i{\‘c}, Filip Jur{\v{c}}{\’\i}{\v{c}}ek, Simon Keizer, Blaise Thomson, Kai Yu, and Steve Young. Spoken language understanding from unaligned data using discriminative classification models. In IEEE International Conference on Acoustics, Speech and Signal Processing, 2009. ICASSP 2009, pages 4749–4752. IEEE, 2009.
[mikolov2010recurrent]: Tomas Mikolov, Martin Karafi{\‘a}t, Lukas Burget, Jan Cernock{`y}, and Sanjeev Khudanpur. Recurrent neural network based language model. In Interspeech, volume~2, page~3, 2010.
[mikolov2013linguistic]: Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic regularities in continuous space word representations. In hlt-Naacl, volume~13, pages 746–751, 2013.
[yao2013recurrent]: Kaisheng Yao, Geoffrey Zweig, Mei-Yuh Hwang, Yangyang Shi, and Dong Yu. Recurrent neural networks for language understanding. In INTERSPEECH, pages 2524–2528, 2013.
[hochreiter1998vanishing]: Sepp Hochreiter. The vanishing gradient problem during learning recurrent neural nets and problem solutions. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 6(02):107–116, 1998.
[Graves2012Supervised]: Alex Graves. Supervised Sequence Labelling with Recurrent Neural Networks. Springer Berlin Heidelberg, 2012.
[yao2014spoken]: Kaisheng Yao, Baolin Peng, Yu~Zhang, Dong Yu, Geoffrey Zweig, and Yangyang Shi. Spoken language understanding using long short-term memory neural networks. In Spoken Language Technology Workshop (SLT), 2014 IEEE, pages 189–194. IEEE, 2014.
[chung2015gated]: Junyoung Chung, Caglar Gulcehre, Kyunghyun Cho, and Yoshua Bengio. Gated feedback recurrent neural networks. In International Conference on Machine Learning, pages 2067–2075, 2015.
[vukotic2016step]: Vedran Vukotic, Christian Raymond, and Guillaume Gravier. A step beyond local observations with a dialog aware bidirectional gru network for spoken language understanding. In Interspeech, 2016.
[vu2016bi]: Ngoc~Thang Vu, Pankaj Gupta, Heike Adel, and Hinrich Sch{\“u}tze. Bi-directional recurrent neural network with ranking loss for spoken language understanding. In 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016.
[zhu2016encoder]: Su~Zhu and Kai Yu. Encoder-decoder with focus-mechanism for sequence labelling based spoken language understanding. In IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP), pages 5675–5679, 2017.
[xu2013convolutional]: Puyang Xu and Ruhi Sarikaya. Convolutional neural network based triangular crf for joint intent detection and slot filling. In IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), 2013, pages 78–83. IEEE, 2013.
[vu2016sequential]: Ngoc~Thang Vu. Sequential convolutional neural networks for slot filling in spoken language understanding. In 17th Annual Conference of the International Speech Communication Association (InterSpeech), 2016.
[yao2014recurrent]: Kaisheng Yao, Baolin Peng, Geoffrey Zweig, Dong Yu, Xiaolong Li, and Feng Gao. Recurrent conditional random field for language understanding. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2014, pages 4077–4081. IEEE, 2014.
[huang2015bidirectional]: Zhiheng Huang, Wei Xu, and Kai Yu. Bidirectional lstm-crf models for sequence tagging. arXiv preprint arXiv:1508.01991, 2015.
[bahdanau2014neural]: Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
[simonnet2015exploring]: Edwin Simonnet, Nathalie Camelin, Paul Del{\‘e}glise, and Yannick Est{`e}ve. Exploring the use of attention-based recurrent neural networks for spoken language understanding. In Machine Learning for Spoken Language Understanding and Interaction NIPS 2015 workshop (SLUNIPS 2015), 2015.
[kurata-EtAl:2016:EMNLP2016]: Gakuto Kurata, Bing Xiang, Bowen Zhou, and Mo~Yu. Leveraging sentence-level information with encoder lstm for semantic slot filling. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2077–2083, Austin, Texas, November 2016. Association for Computational Linguistics.
[liu2016attention]: Bing Liu and Ian Lane. Attention-based recurrent neural network models for joint intent detection and slot filling. In 17th Annual Conference of the International Speech Communication Association (InterSpeech), 2016.
[peng2015recurrent]: Baolin Peng, Kaisheng Yao, Li~Jing, and Kam-Fai Wong. Recurrent neural networks with external memory for spoken language understanding. In Natural Language Processing and Chinese Computing, pages 25–35. Springer, 2015.
[henderson2012discriminative]: Matthew Henderson, Milica Gasic, Blaise Thomson, Pirros Tsiakoulis, Kai Yu, and Stephanie Young. Discriminative spoken language understanding using word confusion networks. In Spoken Language Technology Workshop (SLT), 2012 IEEE, pages 176–181. IEEE, 2012.
[hakkani2006beyond]: Dilek Hakkani-T{\“u}r, Fr{\‘e}d{\‘e}ric B{\‘e}chet, Giuseppe Riccardi, and Gokhan Tur. Beyond asr 1-best: Using word confusion networks in spoken language understanding. Computer Speech & Language, 20(4):495–514, 2006.
[tur2013semantic]: G{\“o}khan T{\“u}r, Anoop Deoras, and Dilek Hakkani-T{\“u}r. Semantic parsing using word confusion networks with conditional random fields. In INTERSPEECH, pages 2579–2583, 2013.
[yang2015using]: Xiaohao Yang and Jia Liu. Using word confusion networks for slot filling in spoken language understanding. In Sixteenth Annual Conference of the International Speech Communication Association, 2015.
[liu2015deep]: Chunxi Liu, Puyang Xu, and Ruhi Sarikaya. Deep contextual language understanding in spoken dialogue systems. In Sixteenth annual conference of the international speech communication association, 2015.
[chen2016end]: Yun-Nung Chen, Dilek Hakkani-T{\“u}r, G{\“o}khan T{\“u}r, Jianfeng Gao, and Li~Deng. End-to-end memory networks with knowledge carryover for multi-turn spoken language understanding. In INTERSPEECH, pages 3245–3249, 2016.
[jaech2016domain]: Aaron Jaech, Larry Heck, and Mari Ostendorf. Domain adaptation of recurrent neural networks for natural language understanding. In INTERSPEECH, 2016.
[kim2016frustratingly]: Young-Bum Kim, Karl Stratos, and Ruhi Sarikaya. Frustratingly easy neural domain adaptation. In COLING, pages 387–396, 2016.
[Zhu2014Semantic]: Su~Zhu, Lu~Chen, Kai Sun, Da~Zheng, and Kai Yu. Semantic parser enhancement for dialogue domain extension with little data. In Spoken Language Technology Workshop (SLT), 2014 IEEE, pages 336–341. IEEE, 2014.
[yazdani2015model]: Majid Yazdani and James Henderson. A model of zero-shot learning of spoken language understanding. In EMNLP, pages 244–249, 2015.
[ferreira2015zero]: Emmanuel Ferreira, Bassam Jabaian, and Fabrice Lef{`e}vre. Zero-shot semantic parser for spoken language understanding. In Sixteenth Annual Conference of the International Speech Communication Association, 2015.
[ferreira2015online]: Emmanuel Ferreira, Bassam Jabaian, and Fabrice Lefevre. Online adaptative zero-shot learning spoken language understanding using word-embedding. In Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on, pages 5321–5325. IEEE, 2015.
[chen2013unsupervised]: Yun-Nung Chen, William~Yang Wang, and Alexander~I Rudnicky. Unsupervised induction and filling of semantic slots for spoken dialogue systems using frame-semantic parsing. In Automatic Speech Recognition and Understanding (ASRU), 2013 IEEE Workshop on, pages 120–125. IEEE, 2013.
[chen2014leveraging]: Yun-Nung Chen, William~Yang Wang, and Alexander~I Rudnicky. Leveraging frame semantics and distributional semantics for unsupervised semantic slot induction in spoken dialogue systems. In Spoken Language Technology Workshop (SLT), 2014 IEEE, pages 584–589. IEEE, 2014.
[chen2015matrix]: Yun-Nung Chen, William~Yang Wang, Anatole Gershman, and Alexander~I Rudnicky. Matrix factorization with knowledge graph propagation for unsupervised spoken language understanding. In ACL (1), pages 483–494, 2015.
[heck2012exploiting]: Larry Heck and Dilek Hakkani-T{\“u}r. Exploiting the semantic web for unsupervised spoken language understanding. In Spoken Language Technology Workshop (SLT), 2012 IEEE, pages 228–233. IEEE, 2012.