论文推荐:zero-shot learning for spoken language understanding(SLU)
zero-shot SLU
论文推荐:zero-shot learning for SLU
引
在传统的口语语义理解中,我们往往都是在一个预先定义好的对话领域(predefined domain)内进行研究,比如领域专家或者开发人员在“航班”领域中定义语义槽(slot)“出发城市”、“出发时间”等,以及每个slot可能对应的值(“出发城市”——“北京,上海,…”、“出发时间”——“上午八点,下午两点,…”等)。
即使假设我们可以负担的起对一个新领域的快速定义(定义用户意图、语义槽值等语义框架),如果我们计划使用有监督学习的方法训练一个语义解析器,那还需要足量的标注数据,比如在“航班”领域中有标注数据——“从[北京:from.city]去[上海:to.city]的机票”。但是,获取大量的标注数据是十分的耗时且人力成本很高的。所以zero-shot learning的原理被引入到SLU中,旨在利用少量甚至数量为零的训练数据得到一个覆盖所有领域内语义项的语义解析器。
zero-shot learning的定义:学习分类器 \(f : X \rightarrow Y \),其中语义类别\(Y\)并没有在训练数据中出现过。即zero-shot learning的目标是为没有观察的标签学习相应的模型。
关于zero-shot learning for SLU的推荐论文如下:
- Online Adaptative Zero-shot Learning Spoken Language Understanding Using Word-embedding. ICASSP 2015.
- Zero-shot Semantic Parser For Spoken Language Understanding. INTERSPEECH 2015.
- Adversarial Bandit For Online Interactive Active Learning Of Zero-shot Spoken Language Understanding. ICASSP 2016.
- A Model of Zero-Shot Learning of Spoken Language Understanding. EMNLP 2015.
- Zero-shot Learning Of Intent Embeddings For Expansion By Convolutional Deep Structured Semantic Models. ICASSP 2016.
作者
Emmanuel Ferreira, Bassam Jabaian and Fabrice Lefe`vre
单位
CERI-LIA, University of Avignon, Avignon - France
关键词
Spoken language understanding, word embedding, zero-shot learning, out-of-domain training data, online adaptation.
来源
ICASSP 2015
立题
不使用语义标注数据,仅使用ontology和外部词向量资源搭建SLU parser。
模型
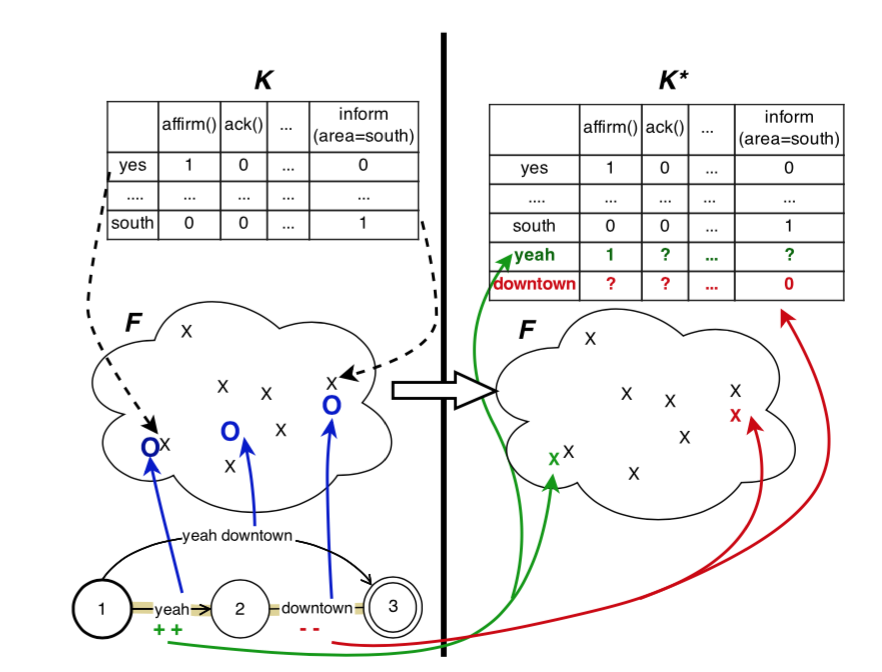
(1)zero-shot learning for SLU
如上图左侧所示,该模型由三部分组成:
- K, 语义知识库。是由ontology导出,每一列是一个acttype-slot-value的三元组,每一行则是该三元组的一个片段描述,比如“affirm()”的片段描述是“yes”、“yeah”等,“request(food)”的描述是“what foof is served”等。这些片段描述的生成可以由一些简单的规则自动生成。
- F,语义特征空间,由外部词向量构成。可以计算不同“片段”之间的相似度。
- 上图左下方的parser。该parser遍历输入句子中的所有“片段”,放入语义特征空间F中和语义知识库K的每一行“片段描述”进行相似度计算,用knn寻找k个最接近的描述片段以及它们对应的acttype-slot-value的三元组。
(2)online adaptation
该文章除了上述不使用训练数据的zero-shot learning方法,考虑到zero-shot parser在实际中使用得到的反馈信息,还设计了一种在线自适应的方法。其反馈为一个0~1的分值 ,0表示negative,1表示positive。在线自适应算法会更新语义知识库K中的表值,如上图右侧所示。
简评
该文章展示了zero-shot learning for SLU的初步工作,为构建一个零标注的语义解析器提供了不错的思路。
作者
Emmanuel Ferreira, Bassam Jabaian and Fabrice Lefe`vre
单位
CERI-LIA, University of Avignon, Avignon - France
关键词
Spoken language understanding, word embedding, zero-shot learning, out-of-domain training data, online adaptation.
来源
INTERSPEECH 2015
立题
不使用语义标注数据,仅使用ontology和外部词向量资源搭建SLU parser。
模型
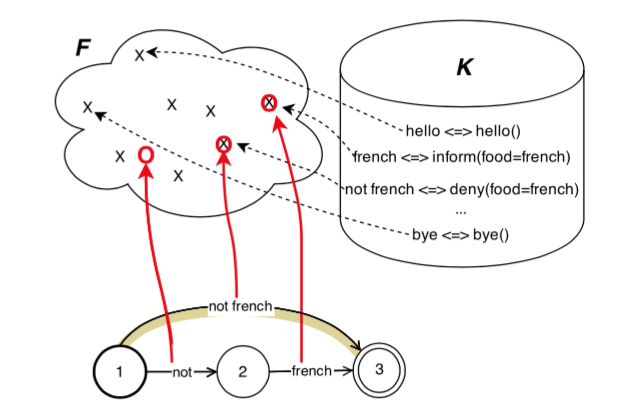 模型组成和上一篇文章是一样的,区别在于该文章引入CRF模型作为后处理模型,且该CRF模型是可扩展的(即可以添加标注数据对该CRF模型进行扩展训练)。
模型组成和上一篇文章是一样的,区别在于该文章引入CRF模型作为后处理模型,且该CRF模型是可扩展的(即可以添加标注数据对该CRF模型进行扩展训练)。
简评
和上一篇文章的思路是一样的,唯一区别就是加入了CRF模型作为可扩展的后处理。
作者
Emmanuel Ferreira, Alexandre Reiffers Masson, Bassam Jabaian and Fabrice Lefe`vre
单位
CERI-LIA, University of Avignon, France
关键词
Spoken language understanding, zero-shot learning, bandit problem, out-of-domain training data, online adaptation.
来源
ICASSP 2016
立题
在上述Zero-Shot Semantic Parser(ZSSP)的基础上深入研究online adaptation方法,达到系统性能和用户付出之间的tradeoff。
模型
引入Adversarial Bandit algorithm Exp3算法学习在线自适应策略(即有:请求用户简单0-1反馈、请求用户标注、跳过,这三个动作)。
简评
文章给出了在线学习的新思路,至于其实用性,有待考证。
作者
Majid Yazdani,James Henderson majid.yazdani@unige.ch, james.henderson@xrce.xerox.com
单位
Computer Science Department University of Geneva; Xerox Research Center Europe
关键词
Spoken language understanding, zero-shot learning, domain expansion
来源
EMNLP 2015
立题
能否建立一个统计SLU模型,可以对训练数据中没有出现过的输入和输出有很好的泛化能力。
模型
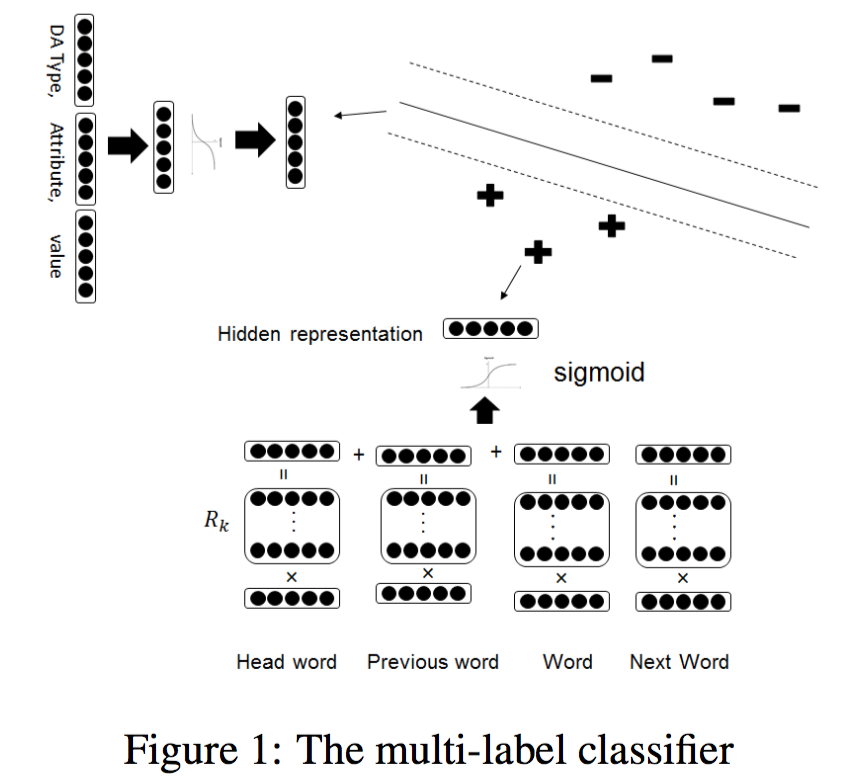 该文章的模型核心是将SLU任务的输入和所有可能输出都用词向量转成分布式的表达,然后用简单的余弦相似度计算输入和可能的输出直接的关联度。
该文章的模型核心是将SLU任务的输入和所有可能输出都用词向量转成分布式的表达,然后用简单的余弦相似度计算输入和可能的输出直接的关联度。
(1)输入的分布式表达
其过程是对句子中每一个位置的词计算得到一个向量表示,再对所有词的向量表示使用池化(pooling)的方法得出句子的分布式表达。计算某一个位置的词的向量表示的公式如下:
$$ \phi(U_i) = \sigma(\phi(w_i)W_{word}+\phi(w_h)W_{parse_{R_k}}+\phi(w_j)W_{previous}+\phi(w_k)W_{next}) $$
其中\(\phi(w)\)是词\(w\)的词向量,\(w_i\)是当前词,\(w_j\)是前一个词,\(w_k\)是后一个词,\(w_h\)是句法依存树上当前词的父节点对应的词,而又根据两者的依存关系\(R_k\)的不同,设置的权值矩阵\(W_{parse_{R_k}}\)也不一样,故\(W_{parse}\)是一个三维tensor。
(2)输出的分布式表达
针对所有可能的输出(比如DAtype-attribute-value三元组),作者也计算它们的分布式表达。计算过程同样利用了词向量,公式:
$$ W_{a_j,att_k,val_l} = \sigma([\phi(a_j),\phi(att_k),\phi(val_l)]W_{ih})W_{ho} $$
即将DAtype,attribute,value三者的词向量串联起来,过两层前馈神经网络。
(3)训练
训练准则如下:
$$ min_{\theta}\ \frac{\lambda}{2}{\theta}^2 + \sum_{U}max(0, 1-y\sum_i \phi(U_i)W_{a_j,att_k,val_l}^T)$$
其中\(\theta\)是模型的所有参数,y为1或者-1(根据输入U中是否包含相应的标签\(\{a_j,att_k,val_l\}\))。
该模型在领域扩展的任务上取得了不错的效果。
资源
词向量:https://code.google.com/p/word2vec/
实验数据:https://sites.google.com/site/parlanceprojectofficial/home/datarepository
相关工作
在SLU中前人的工作主要是基于规则的方法,以及需要大量领域内数据的有监督学习的方法。
简评
该方法对于领域扩展来说是非常实用的一种方法,但对于自适应到全新的领域上的效果还需要质疑。
作者
Yun-Nung Chen⋆† Dilek Hakkani-Tu ̈r† Xiaodong He†
yvchen@cs.cmu.edu, dilek@ieee.org, xiaohe@microsoft.com
单位
⋆Carnegie Mellon University, Pittsburgh, PA, USA
†Microsoft Research, Redmond, WA, USA
关键词
zero-shot learning, spoken language understanding (SLU), spoken dialogue system (SDS), convolutional deep structured semantic model (CDSSM), embeddings, expansion.
来源
ICASSP 2016
立题
该文章专注于intent扩展,打破领域的界限,通过有限的数据,训练一个intent模型可以对数据中没有出现过的intent有很好的泛化能力。
模型
该文章同样期望通过输入输出的分布式表达来获取泛化模型。举个例子来描述这种泛化过程,比如训练数据中出现了intent “find_movie”和“find_flight”,这样模型就可以学习到“find”作为intent一部分时的模式,进而对未在数据中出现过的“find_person”等intent的预测提供帮助。
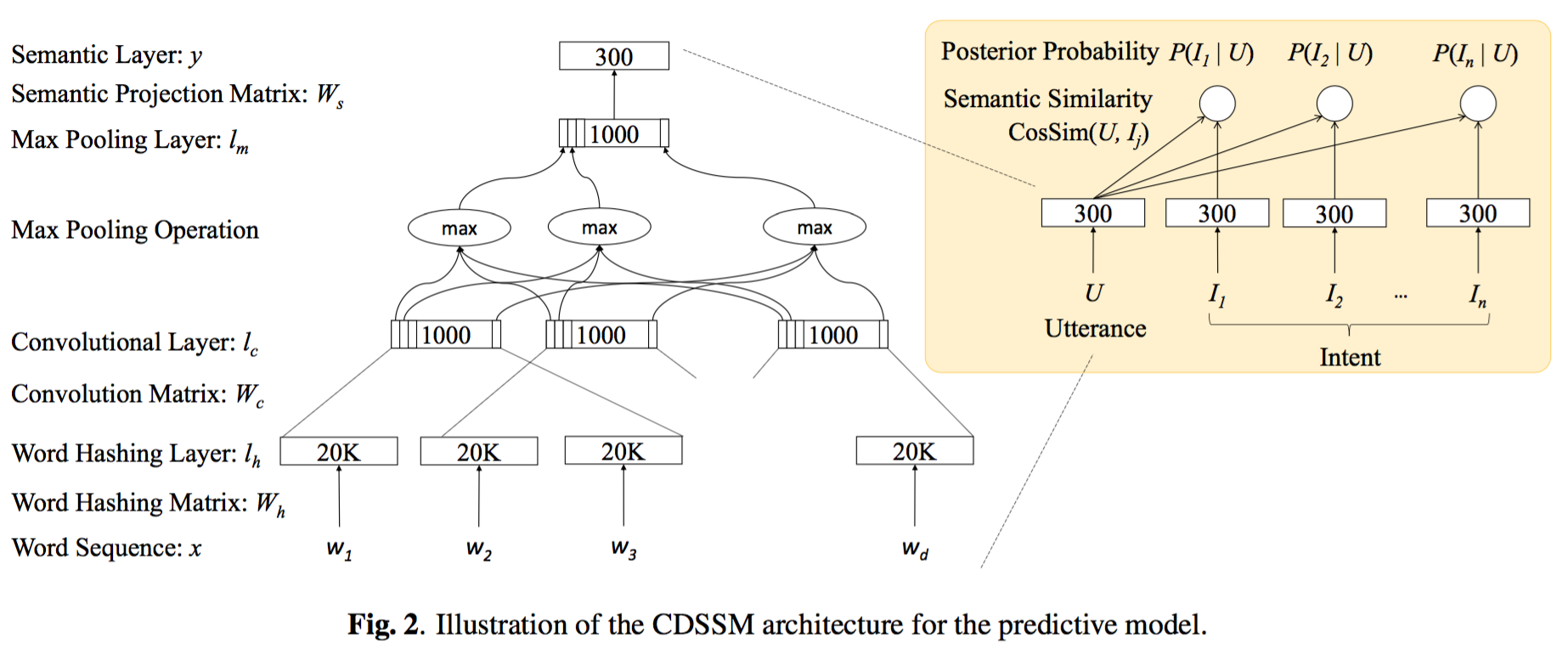 该模型使用余弦距离计算输入和输出的相识度。在训练该模型时,作者提供了两种训练策略,一种基于鉴别式模型,一种基于生成式模型。
该模型使用余弦距离计算输入和输出的相识度。在训练该模型时,作者提供了两种训练策略,一种基于鉴别式模型,一种基于生成式模型。
(1)鉴别式模型
$$P(I|U) = \frac{exp(CosSim(U,I))}{\sum_{I’}exp(CosSim(U,I’))}$$
(2)生成式模型
$$ P(U|I) = \frac{exp(CosSim(U,I))}{\sum_{U’}exp(CosSim(U’,I))} $$
intent detection
针对上述两种模型,该文章给出了两类intent detection方法,一类是两种模型单独计算输入和可能的intent直接的余弦相似度,另一类是将两种模型计算得到的两个相似度加权求和。 $$ S_{Bi}(U,I) = \lambda \cdot S_P(U,I) + (1 − \lambda) \cdot S_G(U,I) $$
相关工作
关于intent expansion,前人有利用知识图谱和搜索引擎click log来做跨领域intent识别的工作。
简评
打破领域解析的intent识别听上去就很诱人。